Issue
-
Jenkins builds can pile up and cause disk space to grow out of control.
-
Jenkins fingerprints can pile up and make your instance run out of inodes (linux).
-
Performance issues can result in large/complex instances with large number of projects building frequently, such as slowdown of the GUI as it attempts to load the job history, etc.
-
Configuring build/fingerprint cleanup following project setup can be manual and time-consuming process, especially with large number of projects.
Resolution
| Builds and fingerprints are correlated. Jenkins maintains a database of fingerprints, Jenkins records which builds of which projects used. This database is updated every time a build runs and files are fingerprinted. |
There are a number of ways to manage build cleanup:
1) By default, you can enable the "Discard Old Builds" in each project/job’s configuration page. Cleanup per project/job is performed after that job runs. "Discard Old Builds" will perform basic cleanup, using functionality found in Jenkins core.
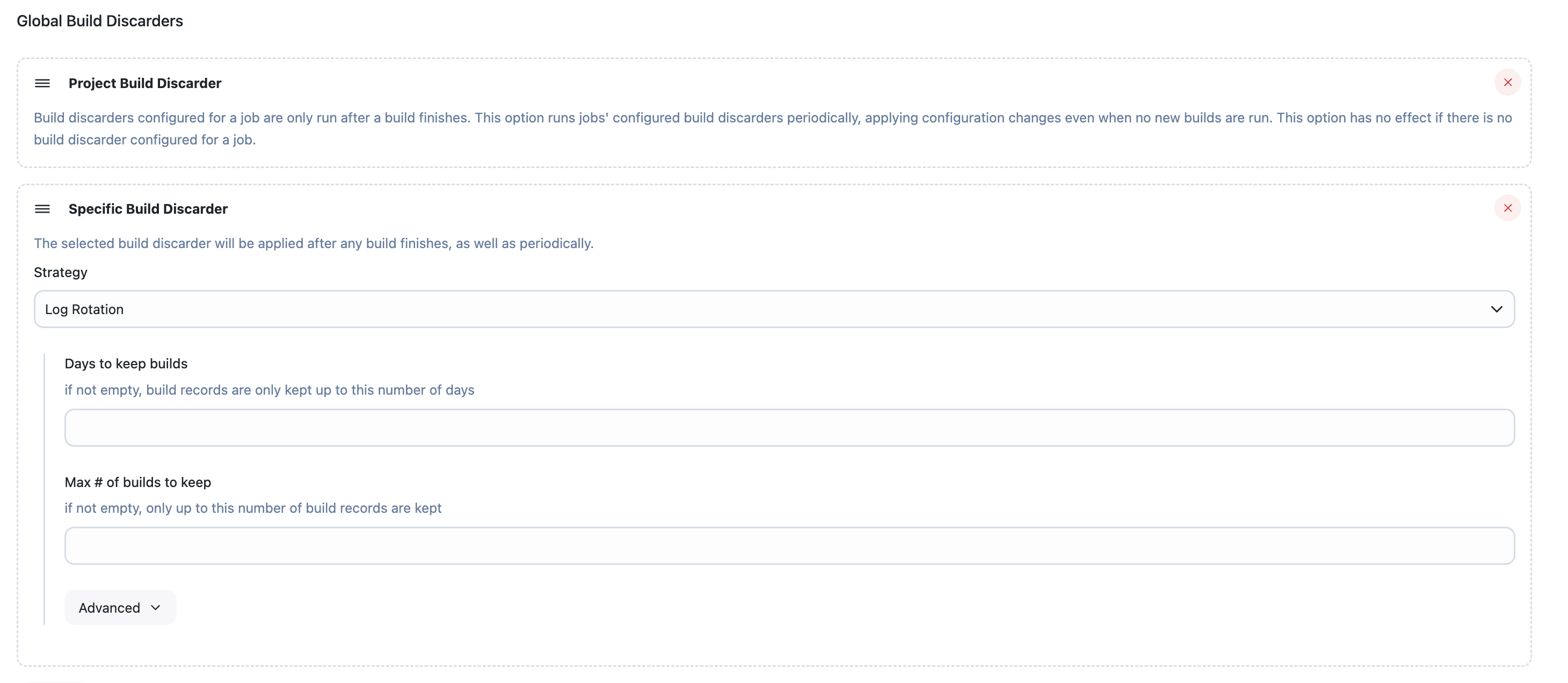
As of v2.221, cleanup will also periodically run using the new Global Build Discarders (even if a job has not recently been run). The global build discarder settings can be accessed from Manage Jenkins > System > Global Build Discarders. The default "Project Build Discarder" requires a project to have the "Discard Old Builds" setting configured. "The Specific Build Discarder" will work across all projects and is the preferred method of applying this functionality across a large number of projects.
2) You can update the configuration of all existing jobs on a Jenkins controller by running the following Groovy Script within Manage Jenkins > Script Console which will apply a permanent build discard policy to your jobs that you can configure by passing the desired values to the listed parameters.
// NOTES:
// dryRun: to only list the jobs which would be changed
// daysToKeep: If not -1, history is only kept up to this day.
// numToKeep: If not -1, only this number of build logs are kept.
// artifactDaysToKeep: If not -1 nor null, artifacts are only kept up to this day.
// artifactNumToKeep: If not -1 nor null, only this number of builds have their artifacts kept.
import jenkins.model.Jenkins
Jenkins.instanceOrNull.allItems(hudson.model.Job).each { job ->
if (job.isBuildable() && job.supportsLogRotator() && job.getProperty(jenkins.model.BuildDiscarderProperty) == null) {
println "Processing \"${job.fullDisplayName}\""
if (!"true".equals(dryRun)) {
// adding a property implicitly saves so no explicit one
try {
job.setBuildDiscarder(new hudson.tasks.LogRotator ( daysToKeep, numToKeep, artifactDaysToKeep, artifactNumToKeep))
println "${job.fullName} is updated"
} catch (Exception e) {
// Some implementation like for example the hudson.matrix.MatrixConfiguration supports a LogRotator but not setting it
println "[WARNING] Failed to update ${job.fullName} of type ${job.class} : ${e}"
}
}
}
}
return;
3) If you are using Templates then it is possible to add a BuildDiscarderProperty like the example below to the template configuration which will add your custom discard policy to each job already created from the template and any future jobs created using the template as well.
<jenkins.model.BuildDiscarderProperty>
<strategy class="hudson.tasks.LogRotator">
<daysToKeep>-1</daysToKeep>
<numToKeep>-1</numToKeep>
<artifactDaysToKeep>-1</artifactDaysToKeep>
<artifactNumToKeep>-1</artifactNumToKeep>
</strategy>
</jenkins.model.BuildDiscarderProperty>
4) If you have large number of existing builds and it’s not feasible to manually cleanup builds using one of the options above, it’s possible to perform manual cleanup of jobs from the filesystem (in $JENKINS_HOME/jobs) following these steps:
-
Stop Jenkins, make sure there are no jobs running
-
Back up
$JENKINS_HOME -
Navigate to
$JENKINS_HOME/jobs/<jobname>/buildsfolder for each project -
Execute the following command to find out how big each build folder is
du -ms */ | sort -n -
Delete the largest build folders (based on the output of the previous step) or every build folder (which comprise the build history).
-
Following the deletion, it will be necessary to restart Jenkins or "Reload Configuration from Disk" (both in "Manage Jenkins") so the links to the deleted builds will disappear.
It’s also possible to purge selectively from the filesystem using find $dir -mtime +$age` where age is the oldest date you want to keep the build (in days). This will get you a list of files older than the chosen date, and you can choose to delete what you feel is safe to remove. Again, you will have to restart or reload once this is done in order for the GUI to show that the builds are no longer available. Be sure to backup your $JENKINS_HOME (or at least the jobs folder) prior to doing this…just in case of unintentional deletes.
| It is possible using the following Groovy Script to delete more builds than intended, these may not be recoverable. |
5) You can also use a Groovy Script to automatically cleanup builds of specific jobs or folders if you can access Manage Jenkins -> Script Console then you can copy the following Groovy script and customize the properties provided within it as necessary:
Automated Groovy Build Clean Script (USE WITH CAUTION)
6) If you ran df -i and saw you were out of inodes, and are not sure which directory in JENKINS_HOME is taking up the most inodes, you can run:
cd JENKINS_HOME # or 'cd JENKINS_HOME/jobs' for f in *; do printf "%s %s\n" "$(find "$f"|wc -l)" "inodes in $f";done|sort -n
The output will be a sorted list, with the number of inodes in a directory and the directory name. For example if you are in JENKINS_HOME/jobs and you run the command with three jobs defined, you will see:
842 inodes in jobA 950 inodes in jobB 83958392 inodes in jobC
Hence the next step is to cd jobC and run the same command again to iterate until you find the specific subdirectory that is using up the most inodes, then decide if you can delete that directory or not.
You could also reach out to your storage provider to see if they can allocate a filesystem with a larger value for -i bytes-per-inode.
Store build artifacts outside of JENKINS_HOME
If jobs are using Archive artifacts or stash, those artifacts are being saved inside of the JENKINS_HOME of the controller. Over time, these artifacts can make your JENKINS_HOME backups large, which increases the time required to backup, the cost of storing multiple backups, and most importantly, how long it takes to revover from a disaster (such as hard drive corruption or accidental deletion). Some possible strategies to deal with this are:
-
Install and configure Artifact Manager on S3 plugin so your artifacts will be stored in an AWS S3 bucket, without you having to modify your job configuration.
-
Instead of archiving the artifacts to the controller, use an artifact repository.
Using the CloudBees Inactive items plugin to find jobs that could potentially be removed
Since version 2.361.2.1 you can take advantage of CloudBees Inactive Items Plugin will analyze different elements in your instance and will help you find inactive items you can safely remove from it. This will allow you go further in the disk space optimization as you will be able to get rid of unused and potentially legacy elements in your instance.
You can find additional information on the plugin configuration and usage in its documentation page: CloudBees Inactive Items Plugin.