Diagnosis/Treatment
Test the connection from Operations Center
Go to Manage Jenkins -> Configure Analytics and hit the button Test Connection.
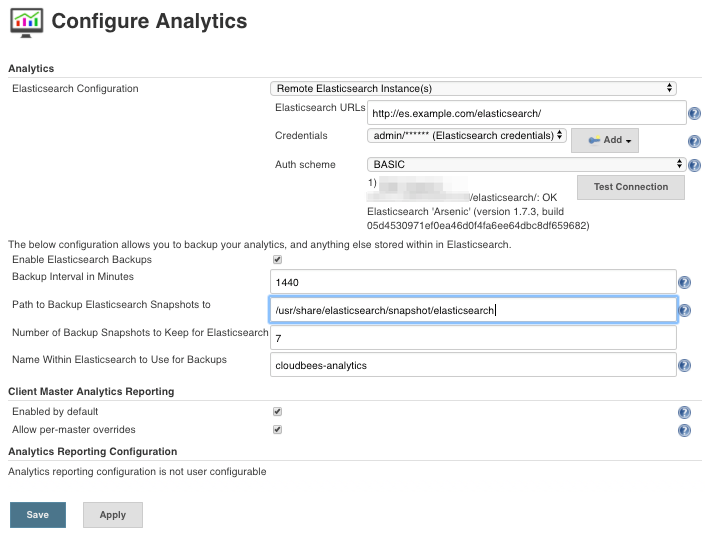
Notice that in case you added Elasticsearch hostname into No Proxy Host in OC, a restart is needed to apply the change.
Compatibility
Check the logs of ES and see which kind of errors you could see in them.
This exception is shown on ES when you try to use an ES more recent than 1.7.X
java.lang.IllegalArgumentException: Limit of total fields [1000] in index [metrics-20170419] has been exceeded at org.elasticsearch.index.mapper.MapperService.checkTotalFieldsLimit(MapperService.java:593) ~[elasticsearch-5.3.0.jar:5.3.0] at org.elasticsearch.index.mapper.MapperService.internalMerge(MapperService.java:418) ~[elasticsearch-5.3.0.jar:5.3.0] at org.elasticsearch.index.mapper.MapperService.internalMerge(MapperService.java:334) ~[elasticsearch-5.3.0.jar:5.3.0] at org.elasticsearch.index.mapper.MapperService.merge(MapperService.java:266) ~[elasticsearch-5.3.0.jar:5.3.0] at org.elasticsearch.cluster.metadata.MetaDataMappingService$PutMappingExecutor.applyRequest(MetaDataMappingService.java:311) ~[elasticsearch-5.3.0.jar:5.3.0] at org.elasticsearch.cluster.metadata.MetaDataMappingService$PutMappingExecutor.execute(MetaDataMappingService.java:230) ~[elasticsearch-5.3.0.jar:5.3.0] at org.elasticsearch.cluster.service.ClusterService.executeTasks(ClusterService.java:679) ~[elasticsearch-5.3.0.jar:5.3.0] at org.elasticsearch.cluster.service.ClusterService.calculateTaskOutputs(ClusterService.java:658) ~[elasticsearch-5.3.0.jar:5.3.0] at org.elasticsearch.cluster.service.ClusterService.runTasks(ClusterService.java:617) ~[elasticsearch-5.3.0.jar:5.3.0] at org.elasticsearch.cluster.service.ClusterService$UpdateTask.run(ClusterService.java:1117) ~[elasticsearch-5.3.0.jar:5.3.0] at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:544) ~[elasticsearch-5.3.0.jar:5.3.0] at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.runAndClean(PrioritizedEsThreadPoolExecutor.java:238) ~[elasticsearch-5.3.0.jar:5.3.0] at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.run(PrioritizedEsThreadPoolExecutor.java:201) ~[elasticsearch-5.3.0.jar:5.3.0] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) [?:1.8.0_65] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) [?:1.8.0_65] at java.lang.Thread.run(Thread.java:745) [?:1.8.0_65]
In the CJOC-embedded Kibana, you could see this exception if you try to connect to a ES upper than 1.7.X
Error: Unknown error while connecting to Elasticsearch
Error: Authorization Exception
at respond (https://0.0.0.0:9292/plugin/operations-center-analytics-viewer/index.js?_b=7562:85289:15)
at checkRespForFailure (https://0.0.0.0:9292/plugin/operations-center-analytics-viewer/index.js?_b=7562:85257:7)
at https://0.0.0.0:9292/plugin/operations-center-analytics-viewer/index.js?_b=7562:83895:7
at wrappedErrback (https://0.0.0.0:9292/plugin/operations-center-analytics-viewer/index.js?_b=7562:20902:78)
at wrappedErrback (https://0.0.0.0:9292/plugin/operations-center-analytics-viewer/index.js?_b=7562:20902:78)
at wrappedErrback (https://0.0.0.0:9292/plugin/operations-center-analytics-viewer/index.js?_b=7562:20902:78)
at https://0.0.0.0:9292/plugin/operations-center-analytics-viewer/index.js?_b=7562:21035:76
at Scope.$eval (https://0.0.0.0:9292/plugin/operations-center-analytics-viewer/index.js?_b=7562:22022:28)
at Scope.$digest (https://0.0.0.0:9292/plugin/operations-center-analytics-viewer/index.js?_b=7562:21834:31)
at Scope.$apply (https://0.0.0.0:9292/plugin/operations-center-analytics-viewer/index.js?_b=7562:22126:24)
Kibana Dashboards are not created
If you see the following error, it means that the Analytics required dashboards are not created, in order to resolve the issue you have to restart CJP-OC, it will recreate the default indices and dashboards.
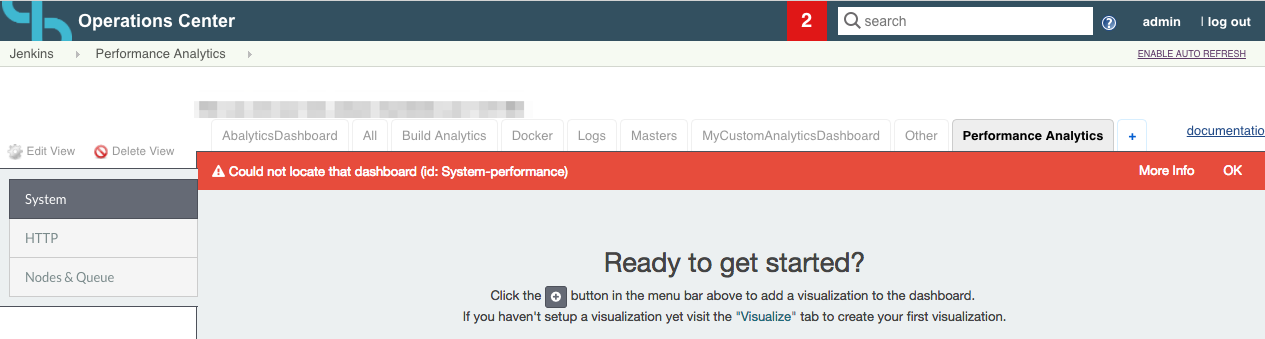
Elasticsearch default index does not exist
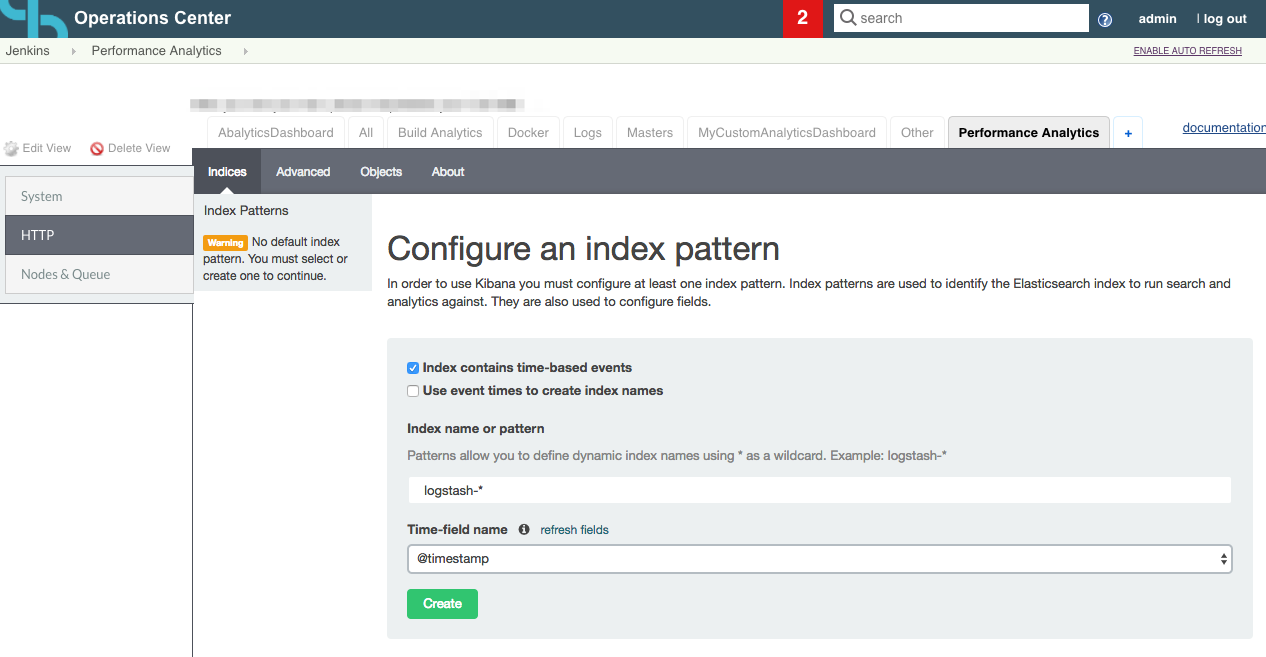
If the default index is not selected, you will see the following page, you only have to select the time-field and click on create, then you can go to another Analytics tab to check that the data is displayed.
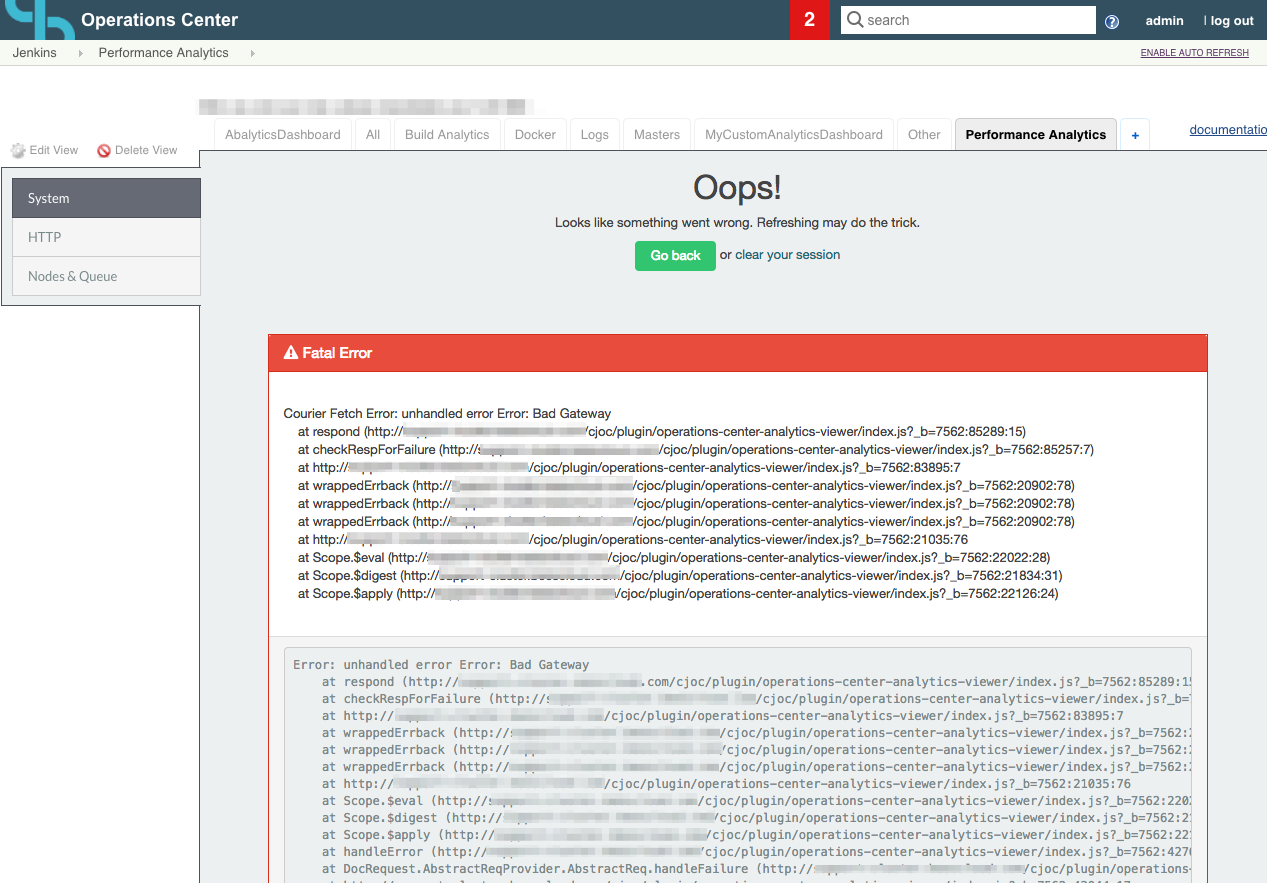
Elasticsearch is not accessible
When it is not possible to contact with the Elasticsearch service you would see the following error, you have to check the connectivity between CJP-OC and the Elasticsearch service, check the health of the Elasticsearch cluster Health, and the Jenkins proxy settings.
Operations Center accessing the Internet through a Proxy
This is by far the most common issue which happens when in Operations Center under Manage Jenkins -> Manage Plugins [Advanced tab] you have a Proxy set-up. In this case, you must add the Elasticsearch hostname to the No Proxy Host section. i.e domain.example.com/elasticsearch. Notice that a restart is needed each time you modify the No Proxy Host section for Analytics to take the changes.
Instead of using the No Proxy Host you can also use the Java argument -Dhttp.nonProxyHosts i.e -Dhttp.nonProxyHosts=domain.example.com/elasticsearch. In the same case than with No Proxy Host a restart is needed for Analytics to take the effect after the Java argument was added to Operations Center.
To test the connectivity between Elasticsearch and Operations Center you can use:
-
The Test Connection button under Manage Jenkins -> Configure Analytics
-
Execute the script below under Manage Jenkins -> Script Consonle
import jenkins.plugins.asynchttpclient.AHC
import com.ning.http.client.AsyncHttpClient
import com.ning.http.client.ListenableFuture
import com.ning.http.client.Response
AsyncHttpClient ahc = AHC.instance()
ListenableFuture<Response> response = ahc.prepareGet("https://<ELASTICSEARCH_HOSTNAME>:9200/").execute()
println(response.get().status.statusCode + " " + response.get().status.statusText)
println("---")
println(response.get().getResponseBody())
In case everything is fine you should get a HTTP 200 answer like the example below:
200 OK
---
{
"status" : 200,
"name" : "Eros",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "1.7.6",
"build_hash" : "c730b59357f8ebc555286794dcd90b3411f517c9",
"build_timestamp" : "2016-11-18T15:21:16Z",
"build_snapshot" : false,
"lucene_version" : "4.10.4"
},
"tagline" : "You Know, for Search"
}
Restart Operations Center after the initial configuration
After first configuration of Analytics a restart is needed to create the index and dashboards.
Recommended Cluster size
We recommend to use a ES cluster with at least three nodes it provides you with fault tolerance for up to 2 nodes crash, these nodes should have about 16-32GB of RAM and 50-200GB of disk it depends of your environment size, if you have more than 10 controllers or more than 10000 jobs you will need a large ES environment to support your load.
Elasticsearch cluster Health
Did you restart your Operations Center after first configuring Analytics? This is necessary to create the index and dashboards. If you did that, you can move on to checking the state of your cluster. Assuming you retrieved the critical information as described above, you can execute the following commands to obtain base information about the health of the Elasticsearch cluster:
export ES_USR="YOUR_USERNAME" export ES_PASSWD="YOUR_PASSWORD" export DOMAIN="ES_HOST:ES_PORT" curl -u $ES_USR:$ES_PASSWD "https://$DOMAIN/_cluster/health?pretty" > health.json curl -u $ES_USR:$ES_PASSWD "https://$DOMAIN/_cat/nodes?v&h=h,i,n,l,u,m,hc,hp,hm,rc,rp,rm,d,fm,qcm,rcm" > nodes.txt curl -u $ES_USR:$ES_PASSWD "https://$DOMAIN/_cat/indices?v" > indices.txt curl -u $ES_USR:$ES_PASSWD "https://$DOMAIN/_cat/shards?v" > shards.txt curl -u $ES_USR:$ES_PASSWD "https://$DOMAIN/_nodes/stats/os?pretty" > stats_os.json curl -u $ES_USR:$ES_PASSWD "https://$DOMAIN/_nodes/stats/os,process?pretty" > stats_os_process.json curl -u $ES_USR:$ES_PASSWD "https://$DOMAIN/_nodes/stats/process?pretty" > stats_process.json
The outputs:
health.json gives you the status of the cluster, shards status, indices status, pendings tasks,.. See Check Cluster Health
{
"cluster_name" : "elasticsearch",
"status" : "red",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 2551,
"active_shards" : 7053,
"relocating_shards" : 0,
"initializing_shards" : 3,
"unassigned_shards" : 6,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 11736,
"number_of_in_flight_fetch" : 0
}
Pay attention to the "number_of_nodes" and "number_of_data_nodes" which should be aligned with the number of nodes you assigned to your elastic search cluster. Besides, you can review resources status (free memory, free disk space, etc.) of the nodes which are currently joined to the cluster looking at nodes.txt. Nodes need to have enough resources to host STARTED shards. For more information, see ES cat API.
h i n l u m hc hp hm rc rp rm d fm qcm 6701a5b2dca8 172.17.0.3 Nico Minoru 2.93 4.4d m 10.3gb 74 13.9gb 29.4gb 57 29.9gb 52.6gb 444.5mb 0b 559932af40d5 172.17.0.3 Fearcontroller 1.93 5d * 10.5gb 75 13.9gb 29.6gb 67 29.9gb 52.6gb 304.6mb 0b 4054511a6f8f 172.17.0.3 Ricadonna 0.18 5d m 5.8gb 41 13.8gb 113.6gb 23 120gb 262.8gb 334.2mb 0b
In case the status of the cluster is yellow or red, next steps would be about investigating the reasons behind that: Which indexes are impacted? How many shards are failing in those indexes? are the primary (red) ore replicas (yellow)?
-
indices.txtstatus (green,yellow,red)
health status index pri rep docs.count docs.deleted store.size pri.store.size green open metrics-hourly-20190405 5 1 160 0 48.3mb 24.2mb green open metrics-20190414 5 1 70958 0 7.9gb 3.9gb green open builds-20190314 5 1 1080 0 3.6mb 1.8mb red open metrics-hourly-20190125 5 1 22 0 7.2mb 3.6mb red open metrics-hourly-20190212 5 1 50 0 12.4mb 6.2mb
-
shards.txtstatus (STARTEDvsUNASSIGNED)
index shard prirep state docs store ip node builds-20170311 8 r STARTED 0 144b 172.17.0.3 Ricadonna builds-20170311 8 r STARTED 0 144b 172.17.0.3 Fearcontroller builds-20170311 8 r UNASSIGNED 0 144b 172.17.0.3 Fearcontroller
stats_os.json, stats_os_process.json, stats_process.json give you general stats of the cluster and nodes, for more info see Nodes Stats
Unassigned Shards
If in your Cluster Health information you see unassigned shards and you do not have a node that is restarting, you have to assign all shards in order to have your cluster on status "green". If you have a node that is restarting you should wait until the node is up and running, and the pending tasks returned by the health check stabilizes
This script is designed to assign shards on a ES cluster with 3 nodes, you have to set the environment variables ES_USR (user to access to ES), ES_PASSWD (password) and, DOMAIN (url to access to ES)
#fix ES shards
export ES_USR="YOUR_USERNAME"
export ES_PASSWD="YOUR_PASSWORD"
export DOMAIN="ES_URL"
export NODE_NAMES=$(curl -u $ES_USR:$ES_PASSWD "$DOMAIN/_cat/nodes?h=h" |awk '{printf $1" "}')
export NODES=(${NODE_NAMES//:/ })
export NUM_UNASSIGNED_SHARDS=$(curl -u $ES_USR:$ES_PASSWD "$DOMAIN/_cat/shards?v" | grep -c UNASSIGNED)
export NUM_PER_NODE=$(( $NUM_UNASSIGNED_SHARDS / 3 ))
export UNASSIGNED_SHARDS=$(curl -u $ES_USR:$ES_PASSWD "$DOMAIN/_cat/shards?v" |grep UNASSIGNED | awk '{print $1"#"$2 }')
export N=0
for i in $UNASSIGNED_SHARDS
do
INDICE=$(echo $i| cut -d "#" -f 1)
SHARD=$(echo $i| cut -d "#" -f 2)
if [ $N -le $NUM_PER_NODE ]; then
NODE="${NODES[0]}"
fi
if [ $N -gt $NUM_PER_NODE ] && [ $N -le $(( 2 * $NUM_PER_NODE )) ] ; then
NODE="${NODES[1]}"
fi
if [ $N -gt $(( 2 * $NUM_PER_NODE )) ]; then
NODE="${NODES[2]}"
fi
echo "fixing $INDICE $SHARD"
curl -XPOST -u $ES_USR:$ES_PASSWD "$DOMAIN/_cluster/reroute" -d "{\"commands\" : [ {\"allocate\" : {\"index\" : \"$INDICE\",\"shard\" : $SHARD, \"node\" : \"$NODE\", \"allow_primary\" : true }}]}" > fix_shard_out_${N}.log
sleep 2s
N=$(( $N + 1 ))
done
Get pending tasks on the ES cluster
Sometimes if you execute the health commands and check the pending tasks, you could see that there are too many, or you see some index on initializing status, to get the details about that tasks you could get the pending tasks of the cluster with these commands, then you can see what happens.
export ES_USR="YOUR_USERNAME" export ES_PASSWD="YOUR_PASSWORD" export DOMAIN="URL_OF_ES" curl -u $ES_USR:$ES_PASSWD -XGET "$DOMAIN/_cluster/pending_tasks?pretty" > pending_tasks.json
Delete index
In you detect problem on an index and it is not possible to fix it, you probably need to delete the index and try to restore it from a snapshot to delete the index you can use these commands
export ES_USR="YOUR_USERNAME" export ES_PASSWD="YOUR_PASSWORD" export DOMAIN="URL_OF_ES" export ES_INDEX="INDEX_NAME" curl -XDELETE -u $ES_USR:$ES_PASSWD "$DOMAIN/$ES_INDEX?pretty"
-
Before deleting an index it might be interesting to create a backup of the current state How to manage Snapshots of your Elasticsearch indices
NOTE: Get Username, password, and ES URL on CJE
If you are on CJE you can get the username, password, and ES URL with these commands
export CJE_PROTOCOL=$(awk '/protocol/ {print $3}' .dna/project.config)
export CJE_DOMAIN=$(awk '/domain_name/ {print $3}' .dna/project.config)
export ES_USR=$(cje run echo-secrets elasticsearch_username)
export ES_PASSWD=$(cje run echo-secrets elasticsearch_password)
export DOMAIN="${CJE_PROTOCOL}://${CJE_DOMAIN}/elasticsearch"