Symptoms
-
Managed controller is failing, its container is being restarted and the Managed controller item log shows
Liveness probe failed: HTTP probe failed with statuscode: 503orLiveness probe failed: Get https://$POD_IP:8080/$CONTROLLER_NAME/login: dial tcp POD_IP:8080: connect: connection refused -
Managed controller is failing, its container is being restarted and the Managed controller item log shows
Readiness probe failed: HTTP probe failed with statuscode: 503orReadiness probe failed: Get https://$POD_IP:8080/$CONTROLLER_NAME/login: dial tcp POD_IP:8080: connect: connection refused -
Managed controller takes a long time to start and eventually fails due to the Liveness or readiness probe
Diagnostic/Treatment
Preconditions
Liveness / Readiness probe failure are caused by Jenkins being not responsive to a health check.
Starting with CloudBees CI version 2.516.1.28665, the Liveness Probe path depends on whether the Use new health check option is configured in a controller’s configure page in the operations center.
-
If enabled, the path is
/$CONTROLLER_NAME/health/?probe=liveness. -
If not enabled, the path is
/$CONTROLLER_NAME/whoAmI/api/json?tree=authenticated
Those failures occurs when CloudBees CI suffers from performance issues and is unresponsive for too long. In most cases, this happens on startup.
Before troubleshooting any further, we recommend to go through the following recommendations that address common causes.
Review Resource Requirements
In containerized environment, it is important that Jenkins gets the resource it needs:
-
Ensure that appropriate container Memory and CPUs are given to the controller (see the "Jenkins controller Memory in MB" and "Jenkins controller CPUs" fields of the Managed controller configuration)
| see also the controller Sizing Guidelines |
Review Startup Performances Preconditions
If the probe fails on startup, review also How to Troubleshoot and Address Jenkins Startup Performances - Preconditions
Workarounds
Liveness / Readiness probe failures suggest performances issues or slow startup. A quick workaround for such kind of issues is to update those probe to give more slack to Jenkins to start or be responsive. But the probe configuration we want to tweak depends on the nature of the problem: is it failing on startup or while Jenkins is running ?
A Probe fails on Startup
If a probe fails while a Managed controller is starting, a quick workaround is to give more time for Jenkins to start (Note that the Liveness probe failure is causing because if it fails it restarts the container).
A Probe fails while Jenkins is running
If a probe fails while a Managed controller is running, it is quite concerning as it suggests that the controller was non responsive for minutes. In such cases, increasing the probes timeout can help to keep the unresponsive controller up for a longer time so that we can collect data.
Data Collection
Although updating the probe configuration can help to get the controller started, it is important to troubleshoot the root cause of the problem, which is usually related to performance.
Failure on startup
If a probe fails while the Managed controller is starting:
-
To troubleshoot the issue further please have a look at How to Troubleshoot and Address Jenkins Startup Performances.
Failure while Jenkins is running
If a probe fails while the Managed controller is running:
-
To troubleshoot the issue further please have a look at Required Data: Jenkins Hang Issue On Linux.
Modifying a liveness/readiness probe on a running instance
If you’d like to modify the values for the liveness or readiness probes, you can either:
1 ) Go to the Operations center and click the gear for a specific managed controller, and under the Configure page, you can change the values:
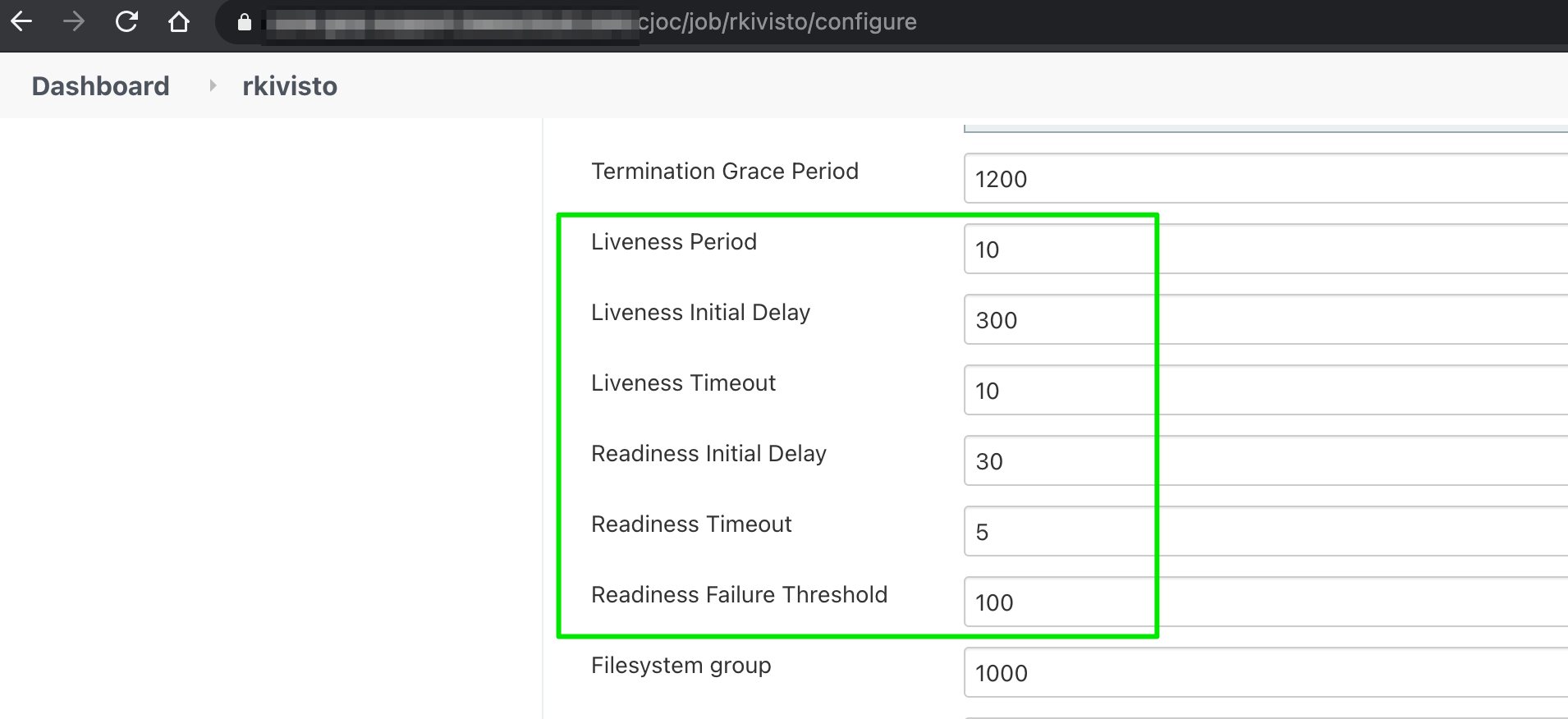
2 ) You can also directly edit the statefulset definition for the pod you would like to change by running:
For the operations center:
kubectl edit statefulset cjoc
or for a specific controller:
kubectl edit statefulset my-controller
and you can directly edit the relevant values:
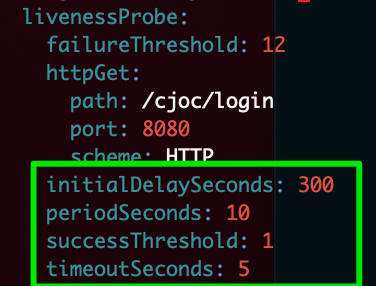
After you save those changes, the pod will be restarted by Kubernetes automatically, and the new values will be applied. Note: this method will only change the values until the next helm modification of the statefulset, or modifications made by the CloudBees CI product, hence this kubectl edit method should only be relied upon for temporary diagnostic purposes.