Question
What are the different possible status values for a step in the CloudBees CD system, and how do these states typically progress?
Solution
The documentation: Property Status, under Object Type: jobStep Description lists 5 different jobStep status values:
pending --the job step was created, but it is waiting for prerequisite steps to complete
runnable --the job step is waiting for a resource
scheduled --the job step was assigned a resource, but the command has not started running
running --the job/job step is running a command on the assigned resource
completed --the job/job step has completed
When a job or process is created, all the steps tied to the current definition of the procedure or process get instantiated as run-time objects.
Each one of the underlying steps is setup with a starting default status of "pending".
These steps are first placed onto a preliminary queue for future processing.
The processing of this queue is handled in a stage called "rechecksubscriptions" which confirms when any step has:
a) Met any precondition
b) Met any runcondition
c) It’s immediate sibling step, or set of parallel sibling steps above this step has completed
When all of these conditions are met, the step status is updated to "runnable".
This will also then move this step onto a queue to be handled by the Step Scheduler (or Resource Scheduler).
ASIDE: What is the Step/Resource Scheduler?
The Step Scheduler is a singleton process that runs on only one of the CloudBees Servers at any time. In other words, having a clustered system does not duplicate this service.
The step scheduler runs regularly at intervals defined by these settings:
-
Maximum time in minutes between runs of the resource scheduler (Default = 10 minutes)
-
Maximum time before resource scheduler commits pending work (Default = 20000 ms)
-
Minimum time before the resource scheduler commits pending work (Pre-v10.1 Default = 1000 ms) (v10.1+ Default = 10000ms)
NEW in v10.0.2/v10.1
-
Maximum number of job steps to process before resource scheduler commits pending work (Default = 500)
-
NOTE: This setting helps to ensure the scheduler doesn’t get bogged down when the queue sizes are very large. If this setting gets used, the next cycle will start reviewing steps inside the queue from wherever the process left off.
While 10 minutes seems like a long time in between kicking the scheduler, this is actually a fallback, as the scheduler, if idle, will also get activated by any of these types of events:
-
A step completes (which frees a resource slot)
-
A resource or workspace is modified
-
A resource becomes available
-
Some less common triggers:
-
Resource pings (similar to the Resource modified)
-
A job is aborted (related to resources being freed up)
-
A getLicenseUsage request is made (one-off)
-
In a busy system, this above list of possible triggers are happening constantly, which means that the scheduler will typically be cycling constantly.
Continuing the jobstep lifecycle
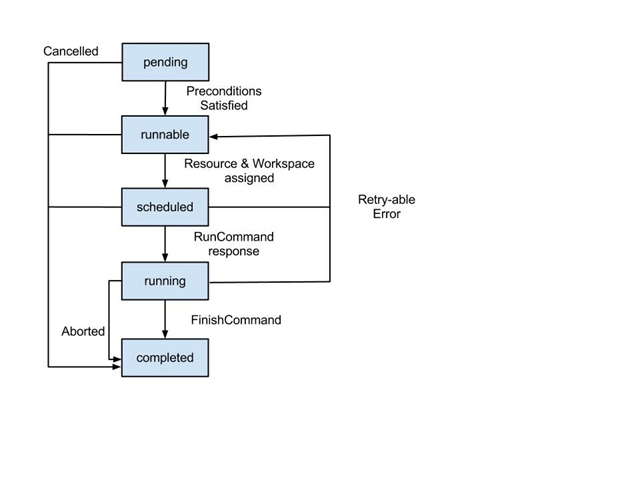
With steps in the job/process now added to the scheduler queue for potential processing, here is how things will then progress:
Once the first step satisfies all possible preconditions, it will be moved over to the runnable state.
Recognize that "first step" might mean a block of steps entering the "runnable" state if there is a parallel block of steps at the start of the job.
If the defined step resource (or a resource from inside the defined pool) and the step defined workspace are available, then the scheduler will mark the step status as "scheduled".
This will activate the step to have it’s defined command block and associated settings shipped to the assigned resource (a RunCommand message) so that the agent software can trigger the work on the remote site.
Once the agent confirms this work assignment has been received, it will acknowledge this to the server, and then the step will be marked as "running" in the database.
In rare timing situations, if the server discovers the assigned resource is not communicating, the step will be placed back into the queue as "runnable" to get another chance to be processed by the scheduler
(perhaps pick another resource from a pool, or wait for the agent to come back alive again).
Assuming the work started on the agent, when this resource confirms that the assigned command block has completed it’s work, it sends a finishCommand back to the server.
When the server receives this message, the jobstep status will move to the "completed" state.
This will also free up the resource slot for pickup by some other step that may be waiting for it when the Scheduler runs it’s next pass.
(The step could also become completed if an abort event is processed by both the server and the agent.)
The agent will keep trying to ship its finishCommand regularly to the server if it is not acknowledging receipt.
This process will continue regularly for 24-hours. Thus, if a server is down for anywhere less than 1 day, the results of the jobStep will still be received by the server when it comes back online.
At that point any dependent steps will move into the scheduler queue to allow the job’s work to continue.