CloudBees CD/RO provides several ways to deploy applications, including deployment policies (such as rolling deployments, blue/green, canary, and dark launch) and deployment options (such as smart deploy, staging artifacts, and error handling). By default, applications are deployed to all resources in the environment at once, and process steps are run sequentially. You can customize how an application is deployed using the options described in Application Deployment Options . For example:
-
When authoring processes, you can define the error handling method for a process step or use rollback.
-
Before the running an application, you can stage artifacts to ensure that all the artifacts are available at runtime, reducing the deployment time.
-
At runtime, you can deploy everything (full run), only changed objects (smart deploy), specific objects (partial run), or snapshots.
In some situations, instead of deploying an application to all machines in the environment at once, it is better to deploy the application in batches.
As you get closer to production environments, reducing the downtime and risk while releasing newer versions becomes business critical. This is especially critical in production environments with live end-user traffic all the time. In some cases, the applications are the backbone of a website and are critical to the business, such as a banking or investment website. Any downtime on the production website can adversely affect the business. CloudBees CD/RO allows modeling the various deployment strategies described in the following sections. The end goals of all these strategies are very similar – reducing the downtime and risk. CloudBees CD/RO also allows modeling strategies such that they can be practiced in lower environments like QA or Pre-Prod to ensure success during production rollouts.
Rolling deployments
One way to reduce the downtime and the risk associated with application deployments is to use rolling deployments . The goal is to minimize downtime to zero or as low as possible without impacting the availability of business critical applications. Rolling deployments are release patterns where the application is gradually deployed to the machines one at a time or in batches. Rolling deployments can be run throughout the release, but they are especially useful near the end of the release process, close to the production environment.
The Rolling Deployment strategy is applicable when the environment caters to end-user traffic and the environments being upgraded is the same.
This is an example of a rolling deployment in a load-balanced environment. When a new version needs to be added to both nodes, it is deployed to the first node while the second node is actively handling the end-user traffic. After the new version is successfully installed on the first node, it starts to handle the end-user traffic while the new version gets applied to the second node. After the new version is successfully installed on the second node, both nodes can actively handle traffic.
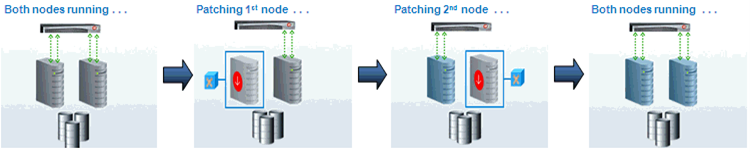
Rolling deployment is an excellent strategy for reducing downtime when you have environments with large numbers of static resources. It is also a cost-effective strategy as no additional resources are required, unlike other strategies. A Rolling deployment generally requires thinking about backward compatibility across the application components.
CloudBees CD/RO natively supports the modeling of rolling deployments for the desired environments. For an environment, you can choose if rolling deployment is enabled. For environments in which you want to run a rolling deployment, you can choose between a phased-based or batch-based deployment.
-
Rolling deployment using phases: This rolling deployment strategy is useful where there is a deterministic mapping between resources and the phase to which they belong. You can either assign resources to phases manually or dynamically using expressions.
-
Rolling deployment using batches: This rolling deployment strategy is useful for environments with large numbers of resources where deterministic mapping between resources and batches is not necessary.
You can decide batch sizes by specifying a number or percentage per tier. Examples are deployment to two resources at a time for the Web tier or to 25% of the resources at a time in the application server tier.
You can also specify a property reference (
$[]). This is useful when you want to apply a property reference to control the batch size based on applications, external configuration files, and so on.See Deployment examples for an example of modeling rolling deployment.
Blue/Green deployments
This technique reduces downtime and risk by running two identical production environments referred to as blue and green . The key difference between rolling deployment and blue/green deployment is that there are two physically separate environments. At any time, only one of these environments is live, serving all of the production traffic. While new versions of the applications are deployed to the second (blue) environment, the first environment (green) is serving production traffic. When the new versions are satisfactorily deployed to the second (blue) environment, all of the end-user traffic (100%) is diverted to it to make it live. After the switch, the green environment becomes inactive and next release can be applied to it and the process can be repeated.
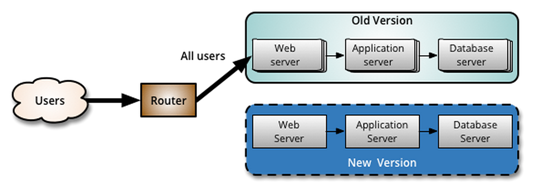
The blue/green deployment strategy is especially useful with dynamic cloud environments. If environments are automatically spun up for every new deployment,the blue/green deployment strategy becomes compelling as the older environment can be decommissioned easily. The blue/green strategy is also useful when it is mandatory to maintain a separate mirrored environment for disaster recovery, as required by some financial companies.
While blue/green deployment makes it much simpler to recover from unforeseen deployment errors, as there are two separate environments, it comes with a higher cost. Because the blue/green strategy requires more than one environment and resource duplication, the overall costs might be higher than rolling deployments.
CloudBees CD/RO allows modeling blue/green deployments with multiple options, but the most logical option is to create separate blue and green environments in the product. These environments are identical for all practical purposes. They can be created before the deployment if they are using static resources, or they can be created dynamically at the deployment runtime using environment templates . Modeling blue and green as separate environments also allows keeping track of the component inventory independently so that users can always know what is deployed to the blue vs green environments at any time.
See Deployment examples for an example of modeling a blue/green deployment.
Canary deployments
This technique is an advanced deployment strategy to reduce the risk of new version rollouts by initially releasing them only to a subset of users. Even a canary deployment strategy typically has two separate environments.
During deployment, new versions are applied to a second inactive environment (as with a blue/green deployment). After the second environment with the newer versions is tested satisfactorily, part of the end-user traffic is diverted to it using a load balancer configuration. The first environment runs the old production versions of the applications and bears the majority of the traffic, while the second environment runs the new versions and handles a small part of the traffic.
This is an effective way to test new versions with live traffic and reduce the risk by containing the exposure. If everything looks fine, all traffic can be diverted to the environment with new versions. Or if the new versions have issues, the older versions can be kept instead.
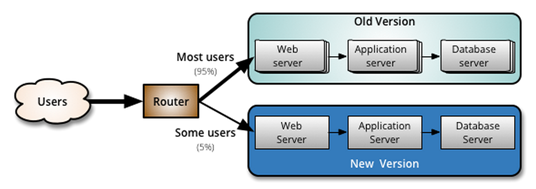
You can model canary deployments natively by creating separate environment objects and then automating loading balancer interactions. These separate environments can be created before the deployment, if they are using static resources, or they can be created dynamically at deployment runtime using environment templates. Modeling them as separate environments also lets you keep track of the component inventory independently so that users can always know what is deployed to which environment at any time.
See Deployment examples for an example of modeling a canary deployment.
Dark launch deployments
You normally use the Dark Launch deployment strategy for deploying new features to a production environment but enabling them only partially or not at all. This is a good practice for testing new code in production without exposing it to end users. This also lets business owners and product managers enable or disable features to test their impact before a wide rollout.
See Deployment examples for an example of modeling a blue/green deployment.
Hot Deployments
A hot deployment strategy typically means changing a running application without causing downtime or without restarting the middleware or infrastructure components that can impact end users. This type of deployment usually depends on the capabilities of the underlying middleware technology. Many application server technologies (such as Tomcat, Red Hat JBoss, IBM WebSphere, and Oracle WebLogic) allow deployments and other adjustments to the application while the server is running. This overcomes a major issue of deployment practices that require a full server restart.
See Deployment examples for an example of modeling a hot deployment.
Partial Deployments
You can deploy only certain objects in scenarios in which other objects are not ready for deployment or you just want to test certain objects independently such as when you want to verify incremental changes. You can also do a partial deployment with only specific artifact versions.
The following screenshot shows how to do a partial deploy with smart deploy and artifact staging enabled:
When you run an application deployment, selecting ![]() opens the list of artifacts and containers that can be deployed in the application process. Artifacts are grouped by application tier. You can enable or disable an artifact within a tier, or the entire tier itself, as part of a deployment.
opens the list of artifacts and containers that can be deployed in the application process. Artifacts are grouped by application tier. You can enable or disable an artifact within a tier, or the entire tier itself, as part of a deployment.
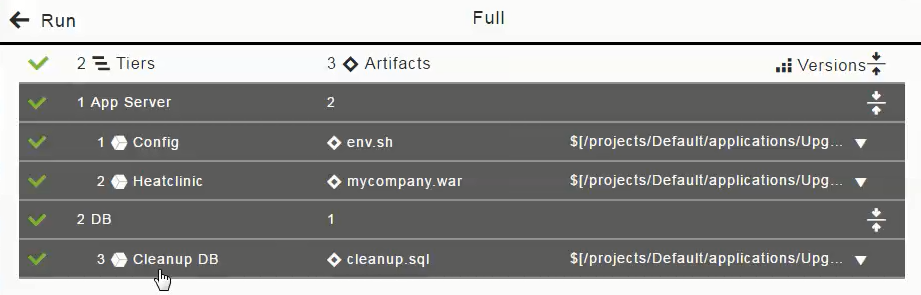
If you want to only deploy the DB artifact (cleanup.sql), click in the "1 App Server" column to deselect (disable the selection of) the Config and Heatclinic components (based on the env.sh and ` mycompany.war` artifacts), and click OK.
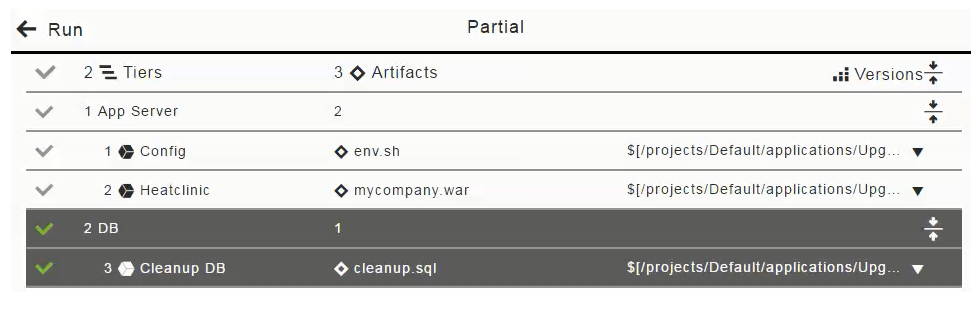
The Artifacts field now looks like this for a partial run:

Other Deployment Strategies
Deployment strategies can be named differently, but they all serve the core purpose of reducing downtime and risk. While modeling such a deployment strategy in CloudBees CD/RO, the best practice is to ask a question–does this strategy require a single environment or multiple environments logically? Based on that answer, you can choose to model using a rolling deployment style, blue/green style, or even a combination. CloudBees CD/RO allows the flexibility to model most of these scenarios.