Run insights capabilities in DevOptics provide CD Platform monitoring and help shared services teams improve DevOps performance by exposing infrastructure inefficiencies, allowing automation constraints to be uncovered and removed. It helps answer the question "Is the CD platform supporting product teams?". It provides you with insights into:
-
Server workloads
-
Job and pipeline activity
-
Details of idle time - how much and when
-
Number of runs waiting to start
-
Length of build request queues
-
Run completion and their status - successful, failed, etc.
-
Optimal time for maintenance/upgrades
Run insights provide you with a real-time and historical view of job and pipeline activity. You can connect any number of masters for an aggregate view across the organization. Masters can be a heterogeneous mix of CloudBees Core and Jenkins. Metrics are viewable over an adjustable time period. You are able to filter run insights by master based on what masters are relevant and important to you.
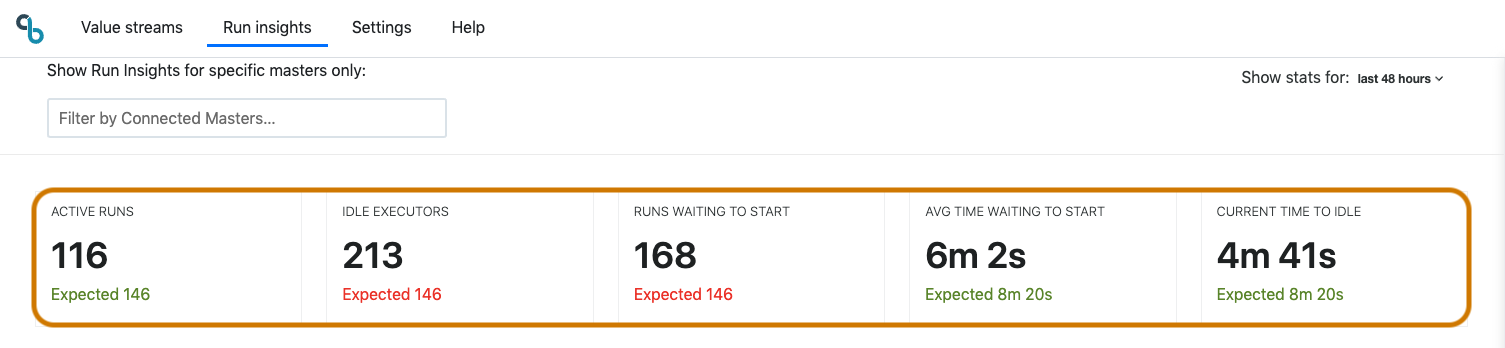
Current activity bar
Provides at-a-glance status into real-time platform activity. Also shows a snapshot of typical values at this day and time. It shows five key pieces of information:
-
Active Runs
-
Idle Executors
-
Runs Waiting to Start
-
Average Time Waiting to Start
-
Current Time to Idle
Active runs
Active runs show how many jobs/pipelines are currently executing. This is the work that all your CI/CD servers are currently processing. This includes all runs that are executing, in the queue, or waiting for user input. It also shows an indication of expected activity for this time and day to easily spot anomalies in real-time.
Idle Executors
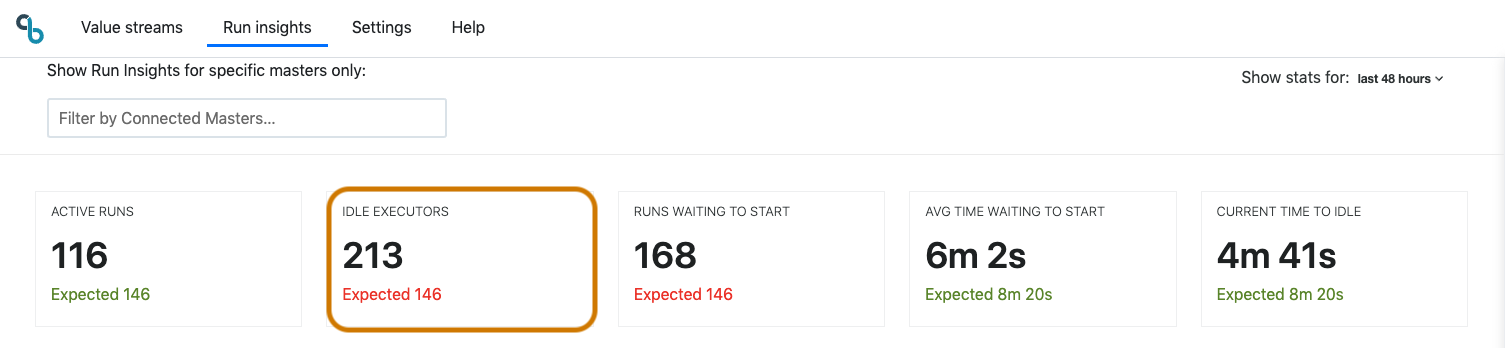
Idle executors show how many executors are currently online and idle. It also shows an indication of expected idle executor count for this time and day to easily spot anomalies in real-time. Online and idle executors are ready to serve teams, but having too many idle executors indicates unnecessary infrastructure costs. If the number of idle executors is high and the number of runs waiting to start is also high, then the load on your cluster may be mismatched or you have jobs/pipelines waiting to start that have restrictions preventing them from running on the available executors.
Runs waiting to start
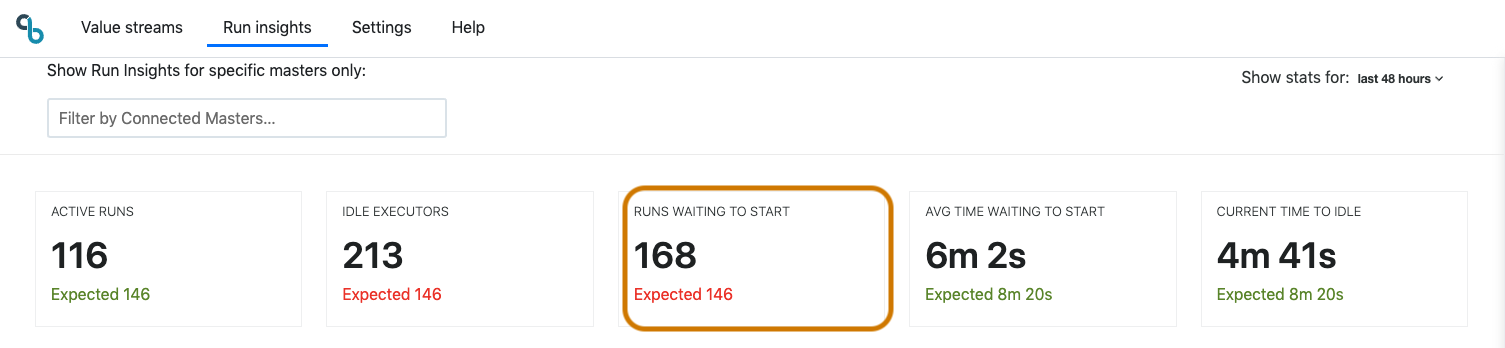
Runs waiting to start shows how many job/pipeline runs are currently in the queue waiting to start. It also shows an indication of expected queue length for this time and day to easily spot anomalies in real-time. The larger this number is, the longer developers have to wait for feedback on the builds that they have triggered, which increases the cost of build failures. Any runs waiting to start are impacting lead time for teams and are an indication that insufficient executor resources are available.
Average time waiting to start
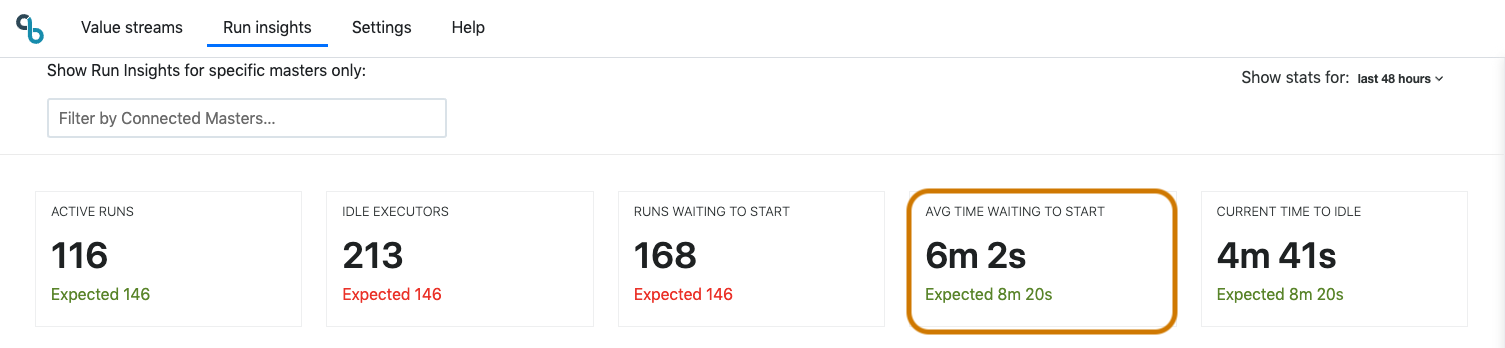
Average time waiting to start shows the average time in the queue for all currently queued build requests. This provides an estimate of how long before builds can start. The metric, along with the number of runs waiting to start, allows you to determine if you have long-running jobs that are preventing other jobs from being executed quickly. At also shows an indication of expected average time waiting to start for this time and day to easily spot anomalies in real-time. Adding more executor slots or removing concurrent execution restrictions should lower this number and represents a quick win for improving the feedback cycle time.
Current time to idle
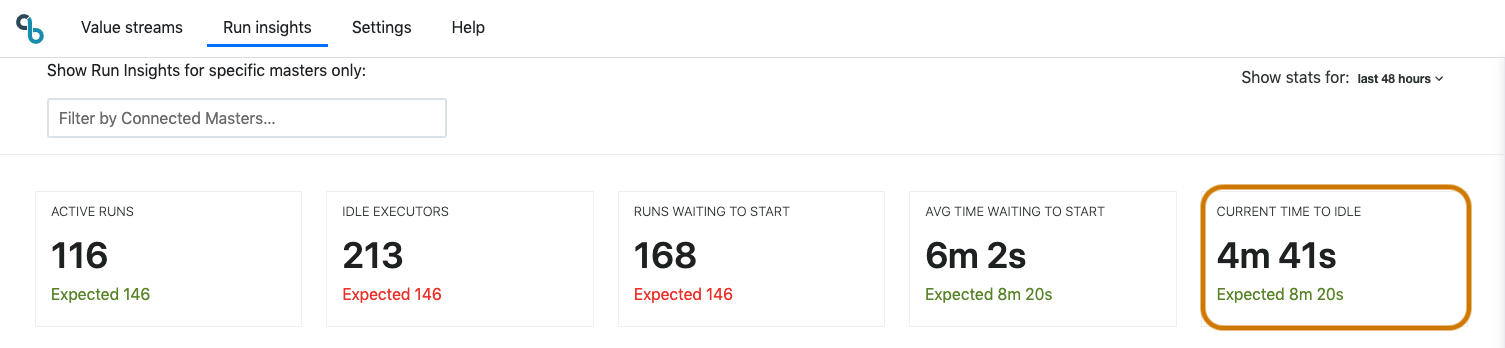
Current time to idle shows an estimation of how long it will be before all currently active jobs are completed. It also shows an indication of expected time to idle for this time and day to easily spot anomalies in real-time. An example use of this status is to help you determine when you can restart your Jenkins master without interrupting active jobs. If you need to restart all the servers in your cluster, this is the earliest time all the builds in progress will be complete, assuming no new builds from the queue are started.
Completed runs
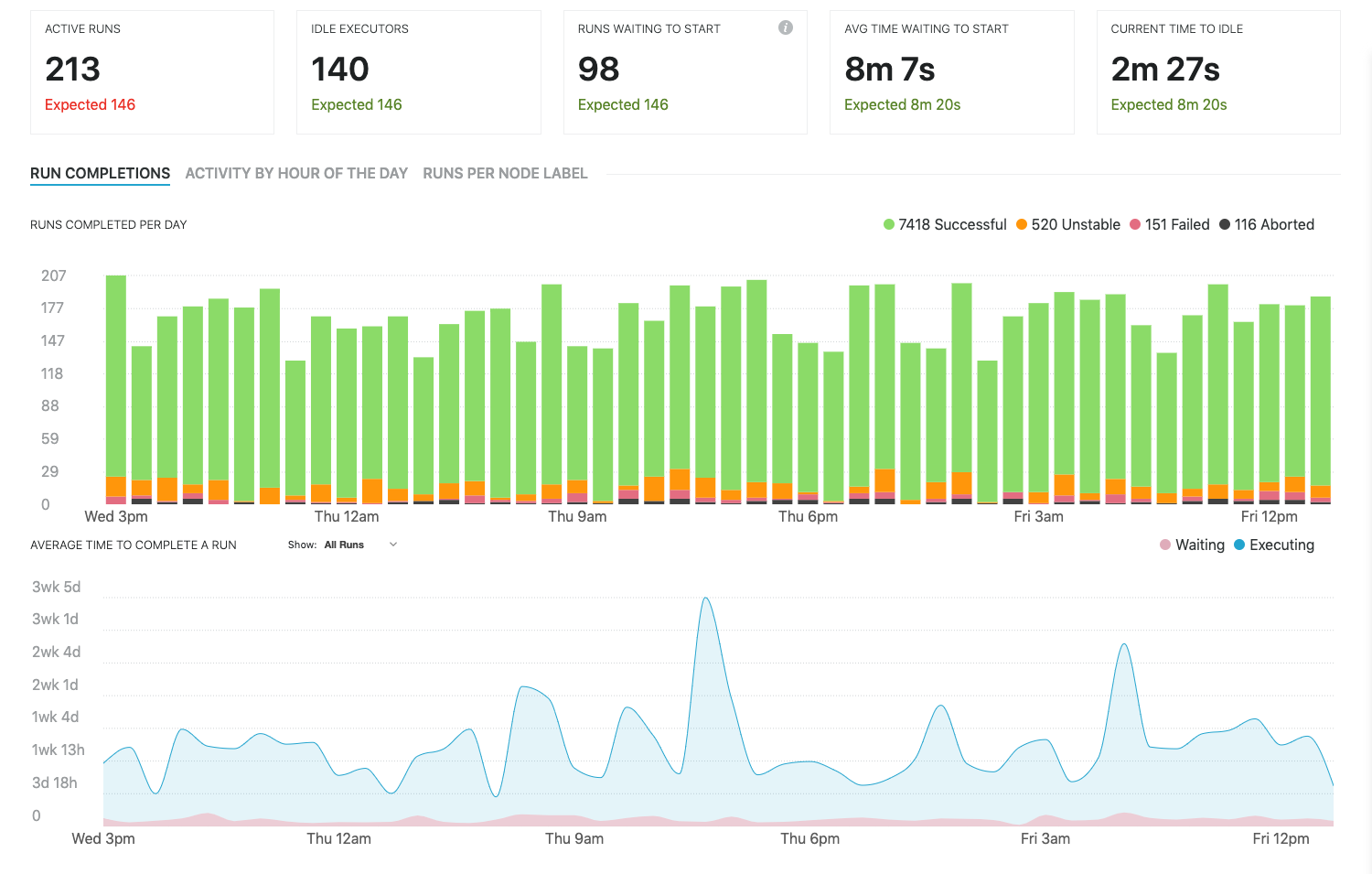
Runs completed per day
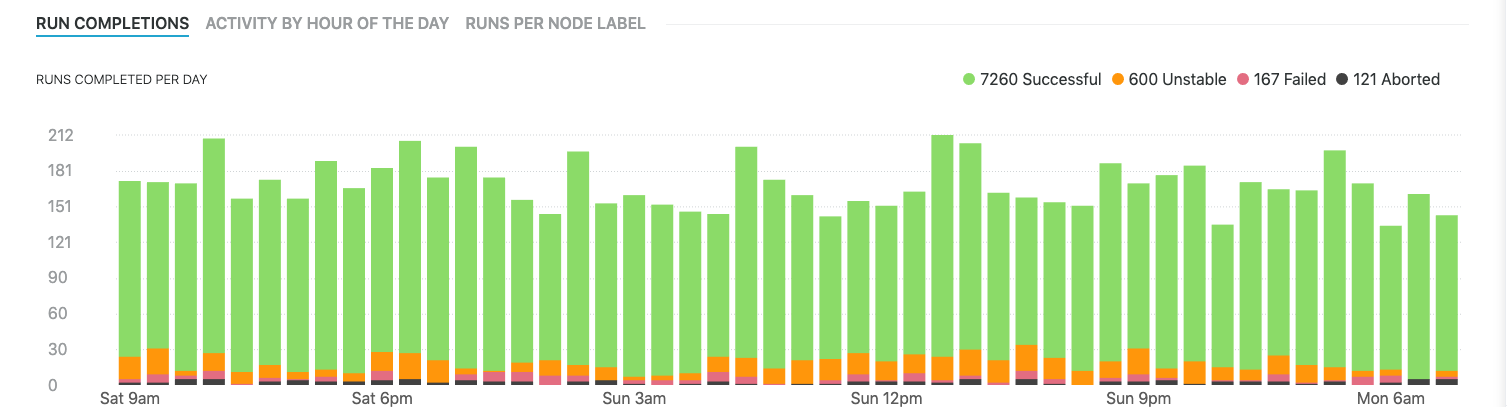
The runs completed per day graph provides a histogram of historical job/pipeline run events. The horizontal axis shows the selected date range, and the vertical axis and the bar length indicate the number of runs. Bars are color-coded to differentiate between the status of runs:
-
Successful (green)
-
Unstable (orange)
-
Failed (red)
-
Aborted (grey)
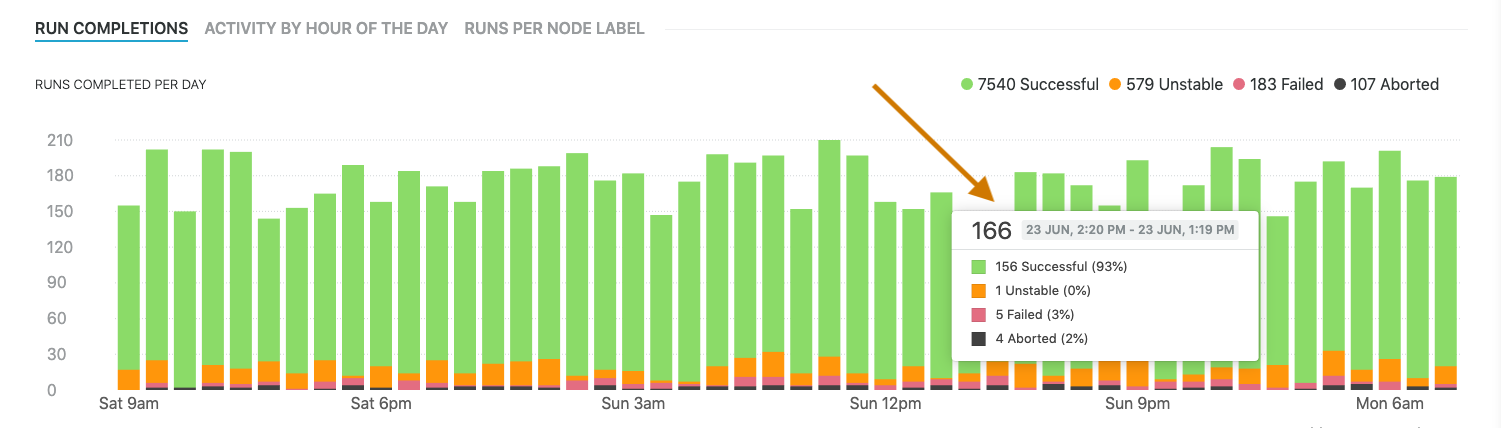
Hovering over a bar will reveal metrics for just the period that the bar represents:
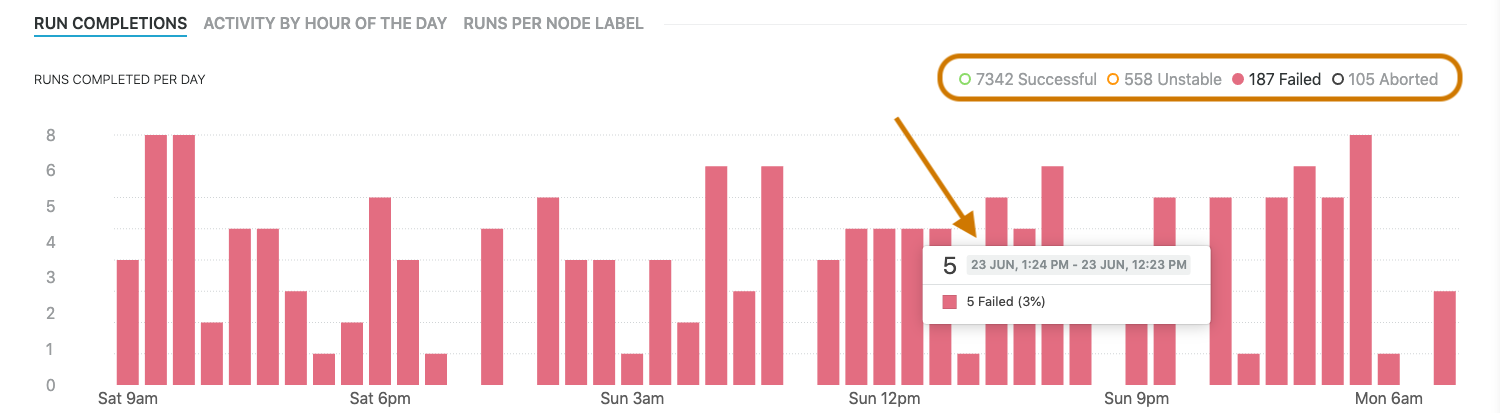
It’s easy to show or hide different states to focus on what is important to you. For example, hiding successful and unstable runs to only show data for failed and aborted runs. Hover metrics are also filtered to show only selected data.
Average time to complete a run
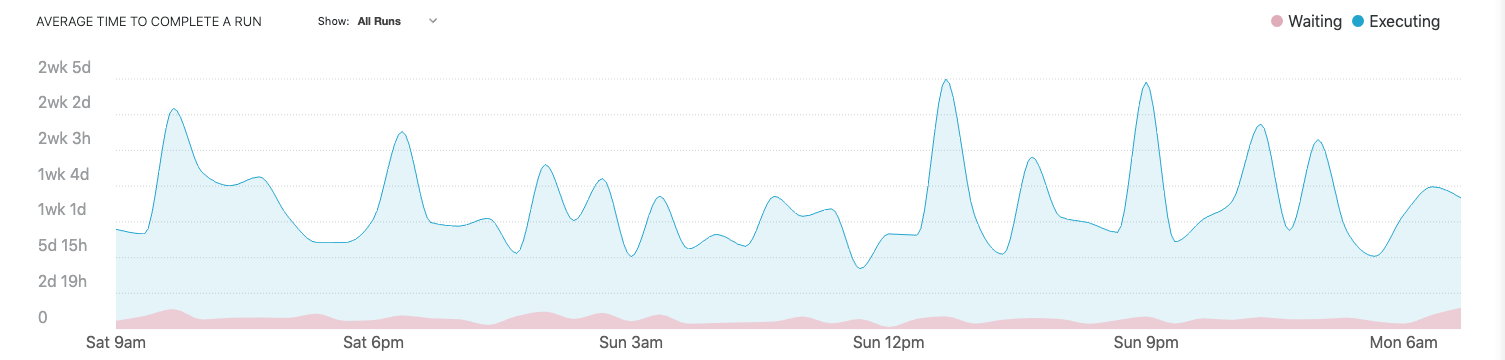
The average time to complete a run graph provides historical analysis of the average time taken to complete runs. Color-coding differentiates active execution time from waiting time. High wait times can indicate a lack of available executors at that time, or that the jobs/pipelines may have had restrictions preventing them from running on the available executors. Long execution times can indicate that jobs running at that time were resource-intensive and that increased resources could potentially allow for them to complete faster and reduce lead times for teams.
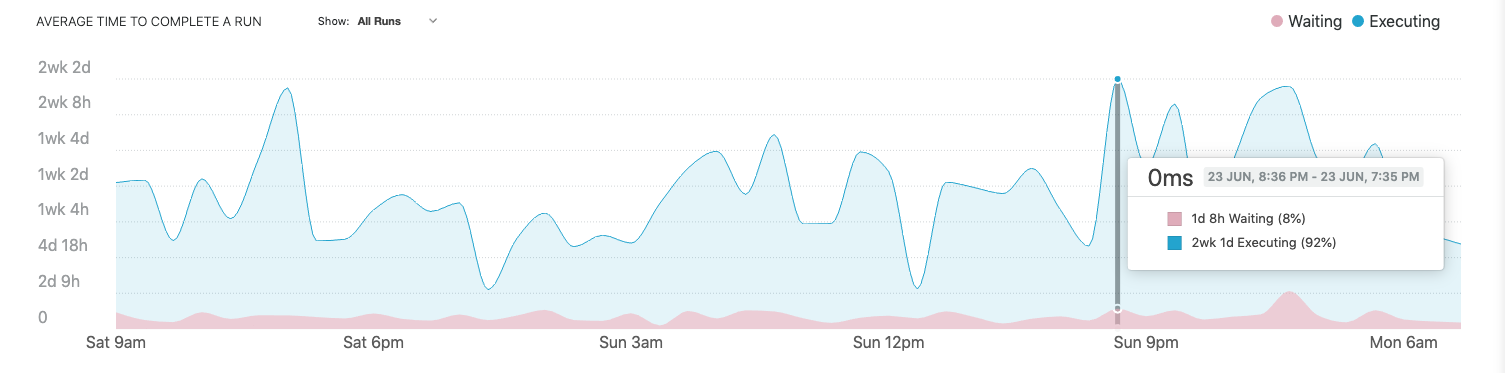
Hovering over a point in time will reveal metrics for just the selected period:
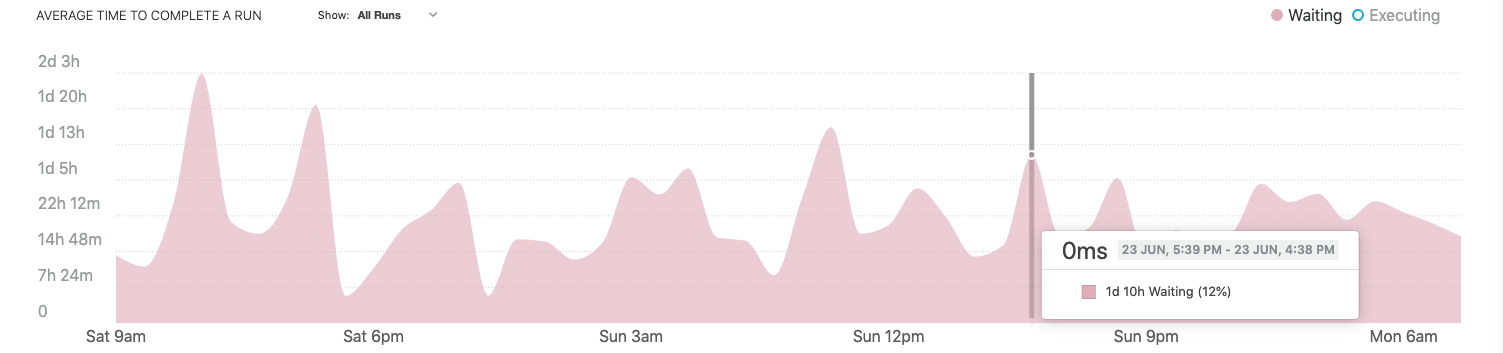
It’s easy to show or hide different states to focus on what is important to you. For example, hiding execution time to update the graph to only show data for waiting time. Hover metrics are also filtered to show only selected data.
Correlations
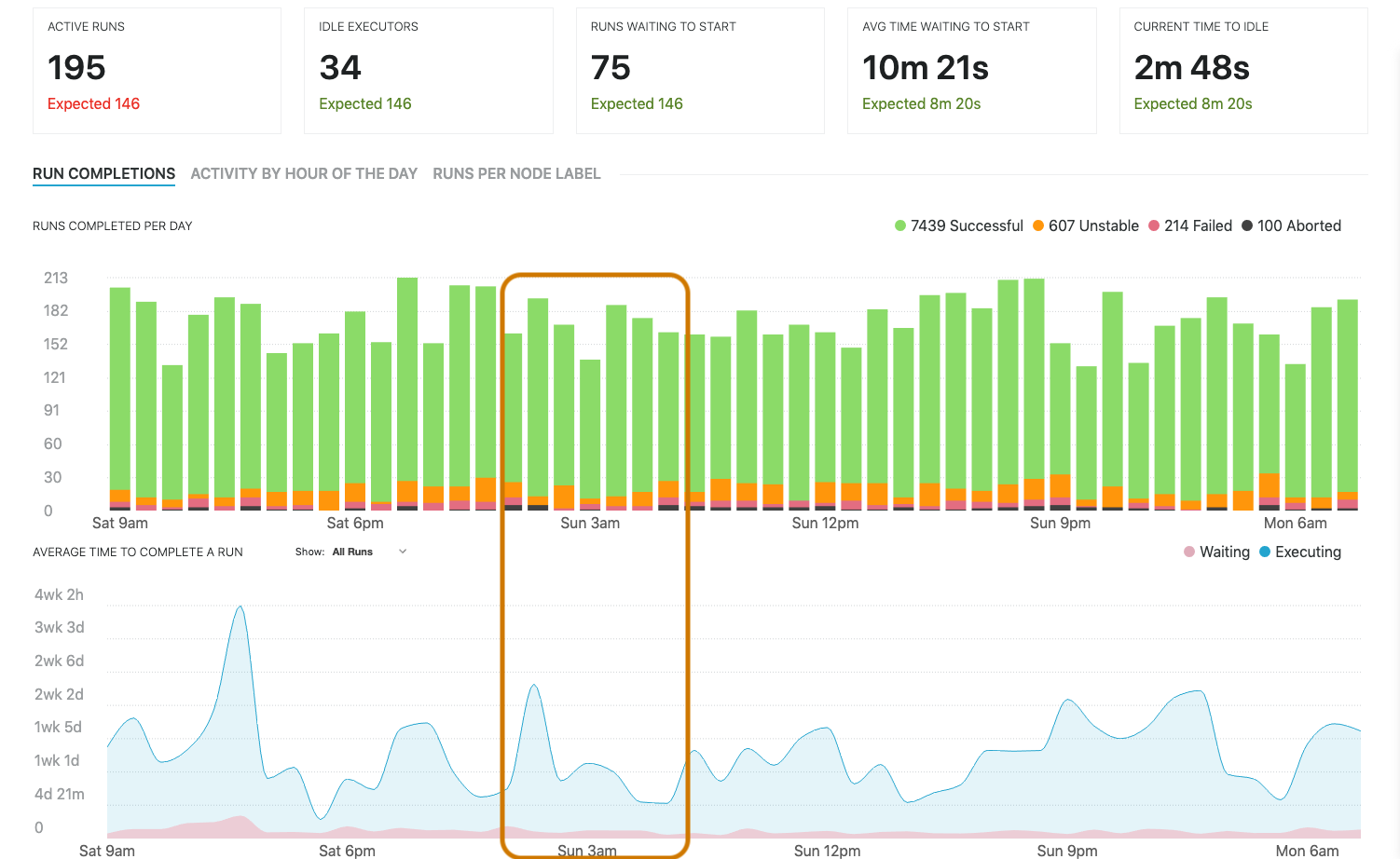
The runs completed per day graph and the average time to complete a run graph are displayed in the same tab because it can be useful to correlate data from both graphs. In this example, we can see correlations between the number of runs and the average execution time. In this case the correlation was caused by resource constraints, and eliminating those resource constraints would allow jobs and pipelines running during busy periods to complete more quickly.
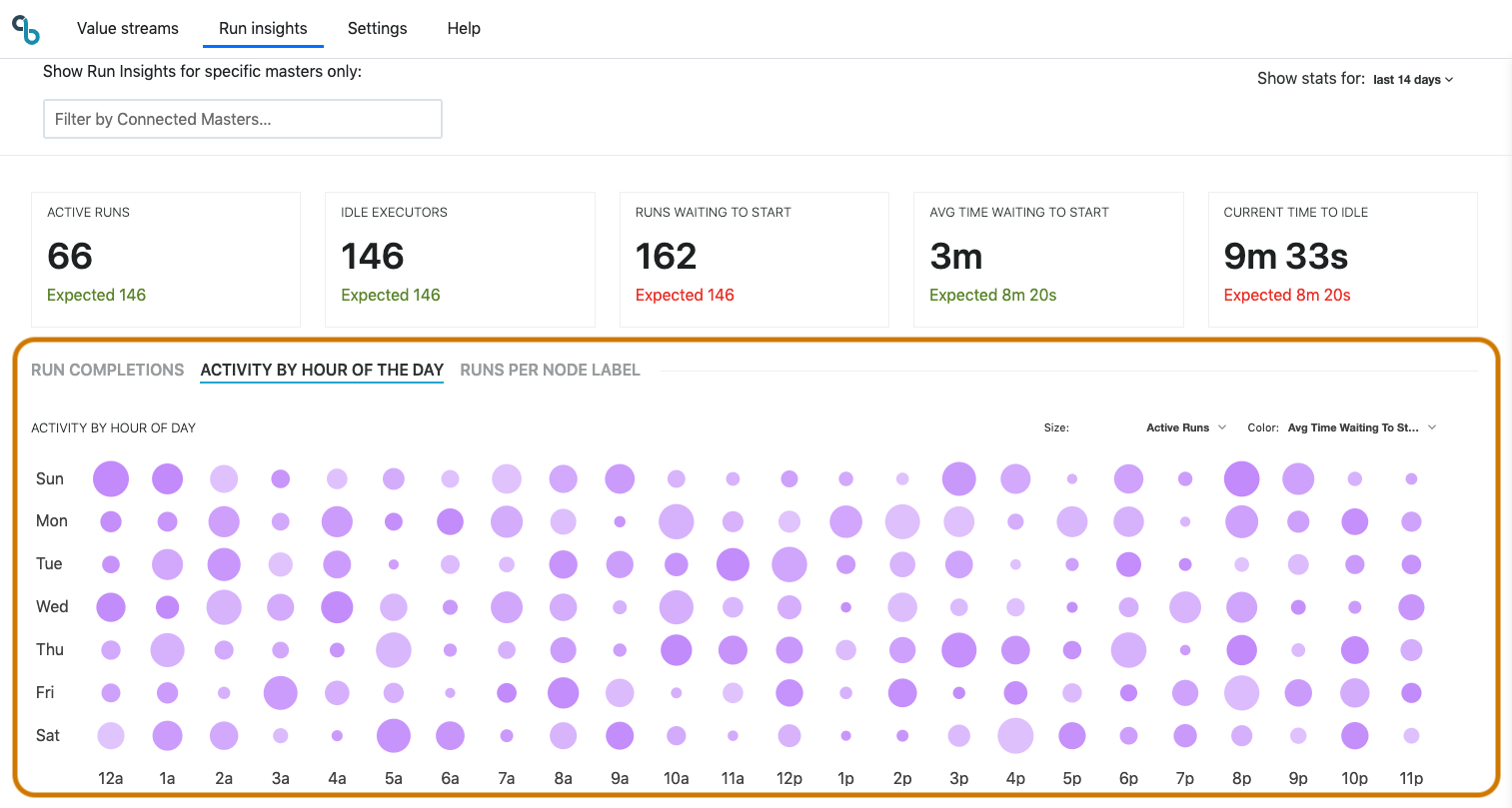
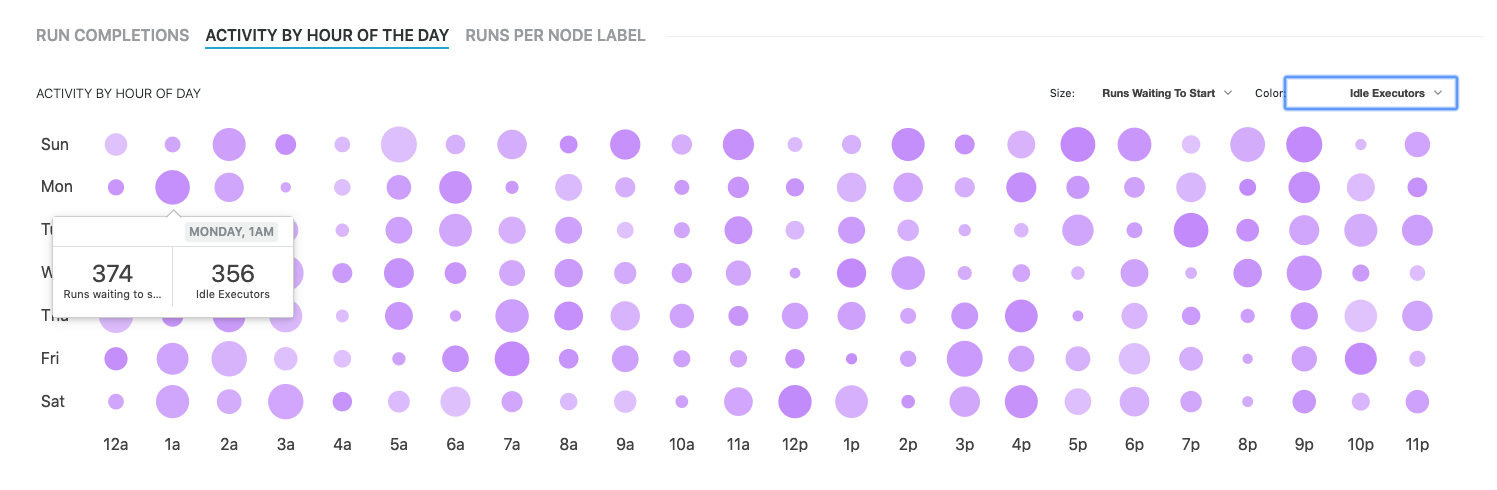
Activity by hour of day
The activity by hour of day graph provides a 24/7 view of CD platform activity. Every hour of every day of the week is represented on the graph. Selectable parameters control the size and color of each bubble to provide analysis flexibility.
Planning maintenance windows
Combining active runs with runs waiting to start allows you to identify time periods where there is typically no or minimal platform activity (running or queued jobs/pipelines). This would be a good time for scheduled maintenance or upgrades.
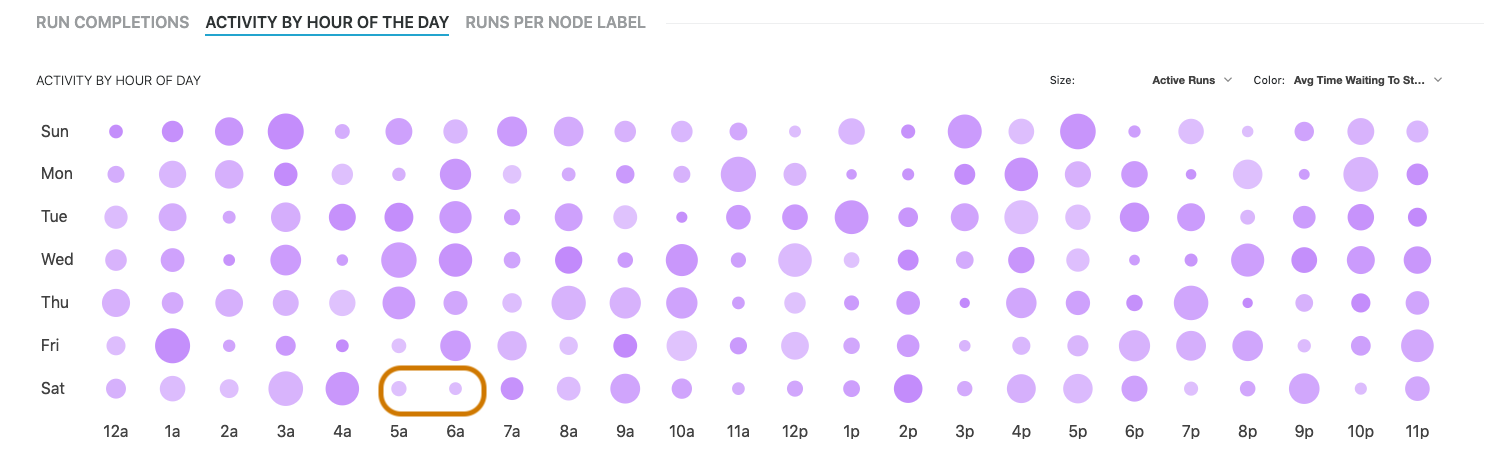
Identifying executor inefficiencies
Combining runs waiting to start with idle executors allows you to identify time periods where the queue length is large and available executors are unable to service the requests. Such a signal implies a poor match of appropriate executor supply/demand. For example, job/pipeline restrictions may be preventing available executors from being used during these times.
Runs by label
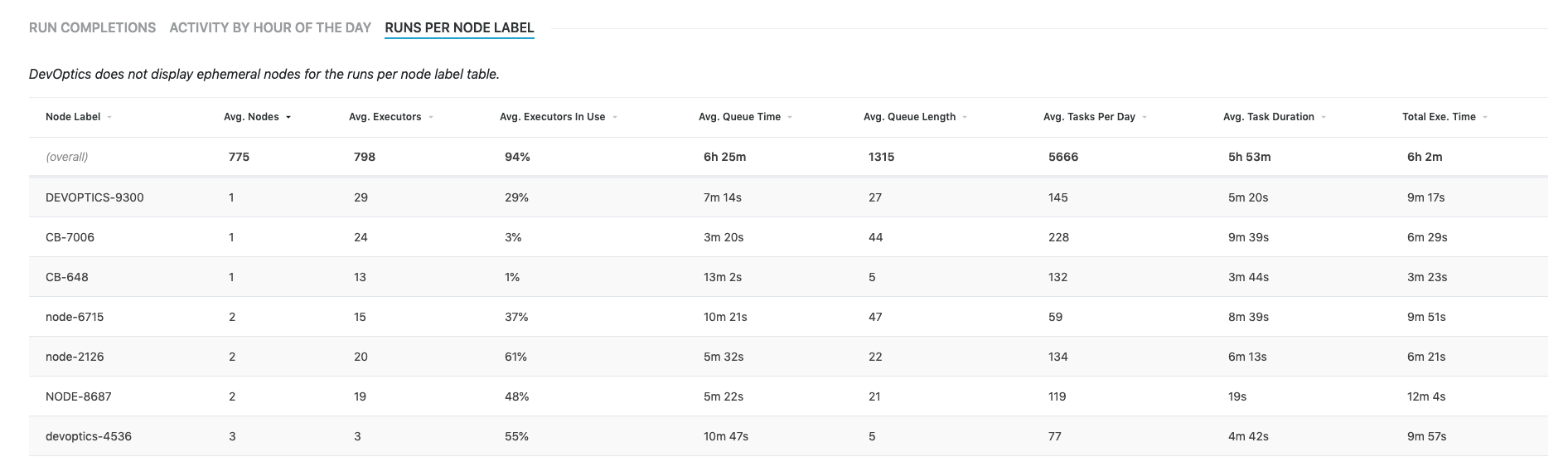
The runs per node label table provides metrics aggregated by label. For each label you should be able to see the following:
-
Average number of nodes: The Average Nodes column displays the average number of nodes that have each label over the selected time period
-
Average number of executors: The Average Executors column displays the average number of executors on nodes that have each label over the selected time period
-
Average executors in use %: The Average Executors in Use column displays the average percentage of used executor capacity for each label
-
Average queue time: The Average Queue Time column displays the average time that jobs spend in the queue for each label over the selected time period
-
Average queue length: The Average Queue Length column displays the average length of the job queue for each label over the selected time period
-
Average tasks per day: The Average Task per Day column displays the average number of tasks that run per day for each label over the selected time period
-
Average task duration: The Average Task Duration column displays the average duration of a task from start to finish on each label over the selected time period
-
Average total execution time: The Average Total Execution Time column displays the average total execution time of all executors running in each job that run on each label over the selected time period
The information in these columns can be useful to determine where you might spend development effort to speed up builds in order to get the most value for your investment. For example:
-
High number of executors in use + high queue length suggests supply is out-stripping demand at certain points in the work day
-
High queue time / high queue length and low average executors may indicate you have jobs set up using label expressions (for example, A && B), and the number of nodes that actually satisfy that are low.
Sort on these columns to better understand build infrastructure usage.
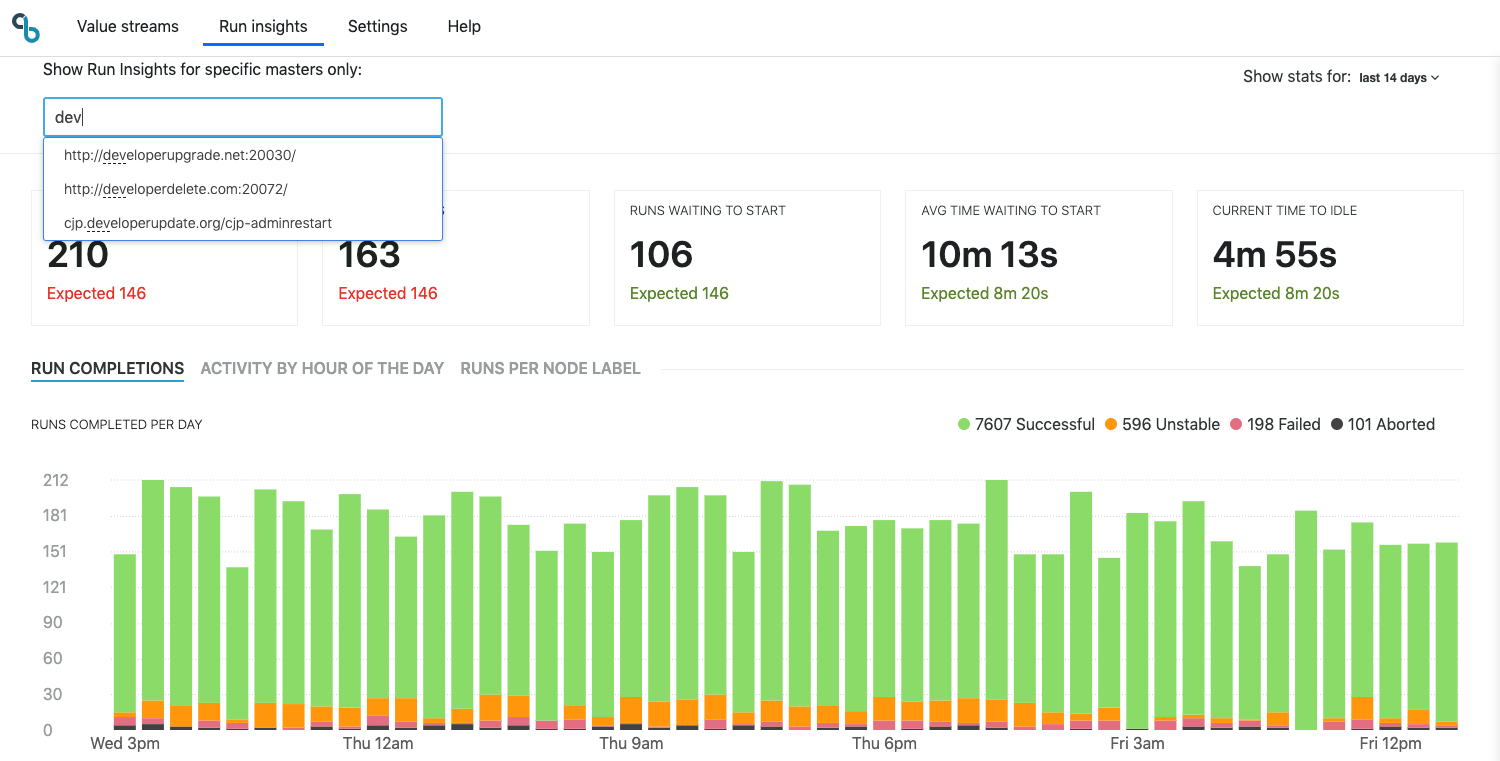
CD platform analysis per master - filtering
Run Insights lets you filter the data per master or group of masters to understand activity and performance of one or more specific masters.
-
You can filter by one or multiple connected masters.
-
You can remove specific masters from the filtered master list or clear all.
-
It stores the filter setting in your local storage, to persist the filter when you return.
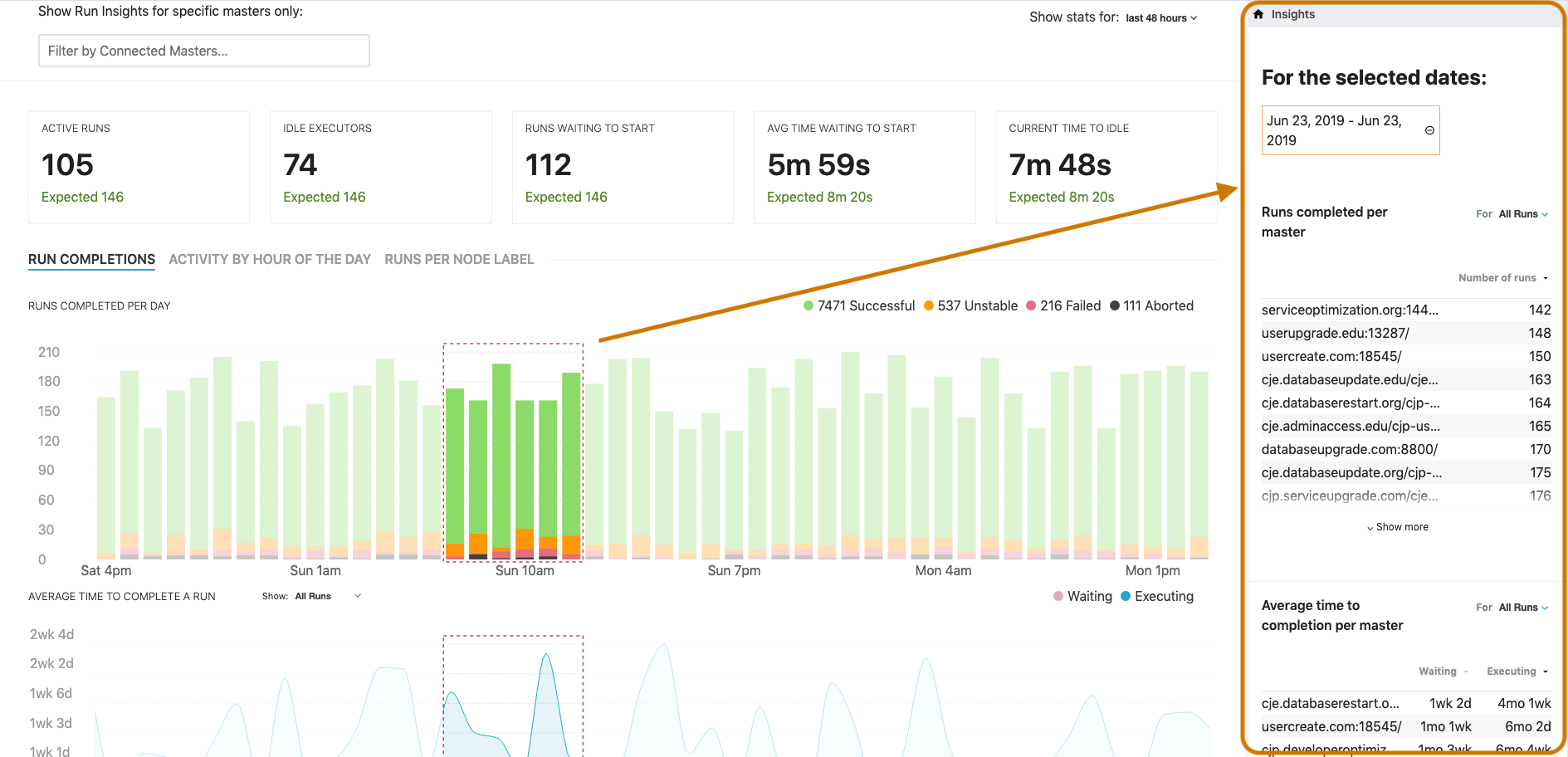
CD platform analysis per master - drill-down
Select a date or a range of dates on the Run Insights graphs to see more granular data points related to the master or masters that contributed to a metric. This helps you to better understand if a certain job is causing long run times or if a master needs to be optimized. You can perform root-cause analysis based on the data that is shown, making it easier to debug and improve performance.
When you select a date or a date range on the Run completions tab, DevOptics shows the 10 masters with the most number of runs and the 10 masters with the highest average time to completion.
Select a time on the Activity by hour tab to see the 10 masters with the highest number of runs waiting to start and the highest average time waiting to start.