To a user, Accelerator might appear identical to other Make versions—reading makefiles in several different formats and producing identical results. Using a cluster for builds is transparent to the Accelerator user.
Following are some important differences in Accelerator build processing versus other distributed systems:
-
Accelerator components work together to achieve faster, more efficient builds. Instead of running a sequential build on a single processor, Accelerator executes build steps in parallel on a cluster of hosts.
-
CloudBees Accelerator Developer Edition components work together to achieve faster, more efficient builds. Instead of running a sequential build on a single processor, CloudBees Accelerator Developer Edition executes build steps in parallel using multiple local agents.
-
For fault tolerance, job results are isolated until the job completes. If an agent fails during a job, Accelerator discards any partial results it might have produced and reruns the job on a different agent.
-
Missing dependencies discovered at runtime are collected in a history file that updates each time a build is invoked. Accelerator uses this collected data to improve performance of subsequent builds.
eMake and EFS
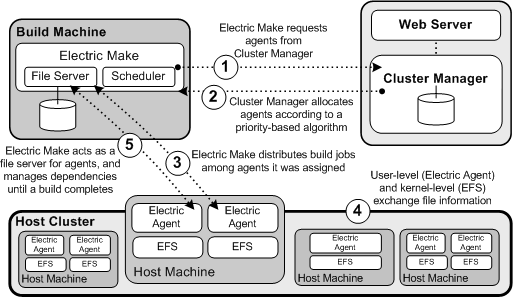
EFS enables high concurrency levels in Accelerator . When a job such as a compilation runs on a host, it accesses files such as source files and headers through EFS. EFS records detailed file-access data for the build and returns that data to eMake.
eMake acts as a file server for agents by dynamically virtualizing the host file system to cluster nodes while the build is running. The agent relays file data from eMake into the kernel, then notifies EFS, which then completes the original request. At the end of a job, the agent returns any file modifications to eMake, so that it can apply changes to its local file systems.
eMake and the Cluster Manager
When eMake is invoked on the build machine, it communicates with the Cluster Manager to acquire a set of agents that it can use for the build. When eMake finishes, it sends the Cluster Manager the build results and tells the Cluster Manager that agents are free now to work on other builds. If more than one build is invoked, the Cluster Manager allocates agents using a priority-based algorithm. Builds with the same priority share agents evenly, while higher-priority builds are allocated more agents than lower-priority builds. By default, agents running on the same host machine are allocated to the same build. In real time, the Cluster Manager dynamically adjusts the number of agents assigned to running builds as each build’s needs change, which allows Accelerator to make the best use of cluster resources.