This section discusses conflicts and conflict detection in eMake. This content was adapted from the How Electric Make guarantees reliable parallel builds and Exceptions to conflict detection in ElectricMake blog posts on https://blog.melski.net/.
How eMake Guarantees Reliable Parallel Builds
The technology that enables eMake to ensure reliable parallel builds is called conflict detection. Although there are many nuances to its implementation, the concept is simple. First, track every modification to every file accessed by the build as a distinct version of the file. Then, for each job run during the build, track the files used and verify that the job accessed the same versions it would have if the build ran serially. Any mismatch is considered a conflict. The erroneous job is discarded along with any file system modifications that it made, and the job is rerun to obtain the correct result.
The Versioned File System
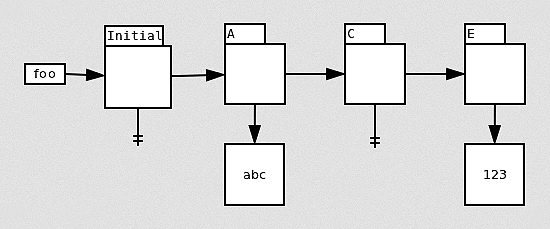
The main part of the conflict detection system is a data structure called the versioned file system, in which eMake records every version of every file used over the lifetime of the build. A version is added to the data structure every time a file is modified, whether that is a change to the content of the file, a change in the attributes (such as ownership or access permissions), or the deletion of the file. In addition to recording file state, a version records the job that created it. For example, here’s what the version chain looks like for a file “foo,” which initially does not exist, then is created by job A with contents “abc”, deleted by job C, and recreated by job E with contents “123”:
Detecting Conflicts
With all the data that eMake collects—every version of every file, and the relationship between every job—the actual conflict check is simple: For each file accessed by a job, compare the actual version to the serial version. The actual version is the version that was actually used when the job ran; the serial version is the version that would have been used, if the build had run serially. For example, consider a job B, which attempts to access a file “foo”. At the time that B runs, the version chain for “foo” looks like this:
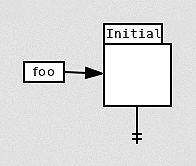
Given that state, B will use the initial version of “foo”—there is no other option. The initial version is therefore the actual version used by job B. Later, job A creates a new version of foo:
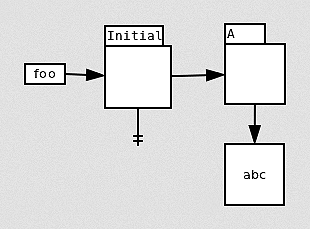
Because job A precedes job B in serial order, the version created by job A is the correct serial version for job B. Therefore, job B has a conflict.
If a job is found to be free of conflicts, the job is committed, meaning that any file system updates are at last applied to the real file system. Any job with a conflict is reverted — all versions created by the job are marked invalid, so subsequent jobs will not use them. The conflict job is then rerun to generate the correct result. The rerun job is committed immediately upon completion.
Conflict checks are done by a dedicated thread that inspects each job in strict serial order. This guarantees that a job is not checked for conflicts until after every job that precedes it in serial order is successfully verified to be free of conflicts. Without this guarantee, the system cannot be sure that it knows the correct serial version for files accessed by the job. Similarly, this ensures that the rerun job, if any, uses the correct serial versions for all files, so the rerun job is sure to be conflict free.
Exceptions to Conflict Detection in eMake
Non-Existence Conflicts
An obvious enhancement is to ignore conflicts when the two versions are technically different, but effectively the same. The simplest example is when there are two versions of a file, which both indicate non-existence, such as the initial version and the version created by job C in this chain for file “foo”:
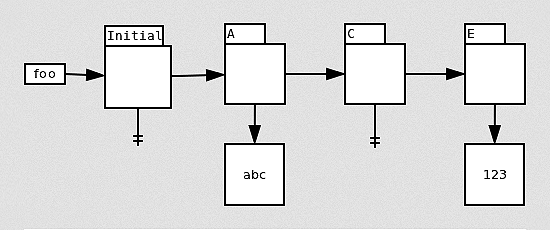
Suppose that job D, which falls between C and E in serial order, runs before any other jobs finish. At runtime, D sees the initial version, but strictly speaking, if it had run in serial order, it would have seen the version created by job C. But the two versions are functionally identical—both indicate that the file does not exist. From the perspective of the commands run in job D, there is no detectable difference in behavior regardless of which of these two versions was used. Therefore, eMake can safely ignore this conflict.
Directory Creation Conflicts
A common make idiom is mkdir -p $(dir $@) —that is, create the directory that will contain the output file, if it doesn’t already exist. This idiom is often used as follows:
$(OUTDIR)/foo.o: foo.cpp @mkdir -p $(dir $@) @g++ -o $@ $^
Suppose that the directory does not exist when the build starts, and several jobs that employ this idiom start at the same time. At runtime, they will each see the same file system state—namely, that the output directory does not exist. Therefore, each job will create the directory. But in reality, had these jobs run serially, only the first job would have created the directory; the others would have seen the version created by the first job, and done nothing with the directory themselves. According to the simple definition of a conflict, all but the first (serial order) job would be considered in conflict. For builds without a history file expressing the dependency between the later jobs and the first, the performance impact would be substantial.
Appending to Files
Another surprisingly-common idiom is to append error messages to a log file as the build proceeds:
$(OUTDIR)/foo.o: foo.cpp @g++ -o $@ $^ 2>> err.log
Each append operation implicitly depends on the previous appends to the file—because the system needs to know which offset the new content should be written to if it does not know how big the file was to begin with. In terms of file versions, a naive implementation treating each append to the file as creating a complete new version of the file is possible:
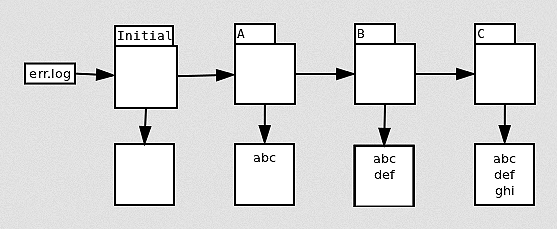
Of course, the is that conflicts will occur if you try to run all of these jobs in parallel. Suppose that all three jobs, A, B and C start at the same time. They will each see the initial version, an empty file, but if run serially, only A would have seen that version. B would have seen the version created by A; C would have seen the version created by B.
This example is particularly interesting, because eMake cannot sort this out on its own: As long as the usage reported for err.log is the very generic “this file was modified, here’s the new content” message normally used for changes to the content of an existing file, eMake has no choice but to declare conflicts and serialize these jobs. Fortunately, eMake is not limited to that simple usage record. The EFS can detect that each modification is strictly appending to the file (with no regard to the prior contents) and includes that detail in the usage report. Thus informed, eMake can record fragments of the file, rather than the entire file content:
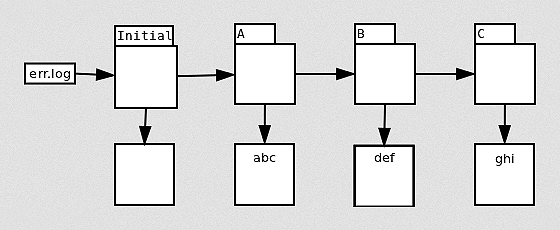
Because eMake now knows that the jobs do not depend on the prior content of the file, it need not declare conflicts between the jobs, even if they run in parallel. As eMake commits the modifications from each job, it stitches the fragments together into a single file with each fragment in the correct order relative to the other pieces.
Directory-Read Conflicts
Directory-read operations are interesting from the perspective of conflict detection. Consider: What does it mean to read a directory? The directory has no content of its own, not in the way that a file does. Instead, the “content” of a directory is the list of files in that directory. To check for conflicts on a directory read, eMake must check whether the list of files that the reader job actually saw matches the list that it would have seen had it run in serial order—in essence, doing a simple conflict check on each of the files in the directory.
That is s conceptually easy to do, but the implications of doing so are significant: It means that eMake will declare a conflict on the directory read anytime any other job creates or deletes any file in that directory. Compare that to reads on ordinary files: You only get a conflict if the read happens before a write operation on the same file. With directories, you can get a conflict for modifications to other files entirely.
This is particularly problematic, because many tools actually perform directory reads in the background, and often those tools are not actually concerned with the complete directory contents. For example, a job that enumerates files matching *.obj in a directory is only interested in files ending with .obj. The creation of a file named foo.a in that directory should not affect the job at all.
Another problematic example comes from utilities that implement their own version of the getcwd() system call. If you want to create your own version, the algorithm looks something like this:
-
Let
cwd= “” -
Let
current= “.” -
Let
parent= “./..” -
Stat
currentto get its inode number. -
Read
parentuntil an entry matching that inode number is found. -
Add the name from that entry to
cwd. -
Set
current=parent. -
Set
parent=parent+ “/..” -
Repeat starting with step 4.
By following this algorithm, the program can construct an absolute path for the current working directory. The problem is that the program has a read operation on every directory between the current directory and the root of the file system. If eMake strictly adhered to conflict checking on directory reads, a job that used such a tool would be serialized against every job that created or deleted any file in any of those directories.
For this reason, eMake deliberately ignores conflicts on directory-read operations by default. Most of the time, this is safe to do, because often tools do not need a completely accurate list of the files in the directory. And even if the tool does require a perfectly correct list, the tool follows the directory read with reads of the files that it finds. This means that you can ensure correct behavior by running the build one time with a single agent to ensure the directory contents are correct when the job runs. That run will produce history based on the file reads, so subsequent builds can run with many agents and still produce correct results.
You can also do one of the following:
-
Use
–emake-readdir-conflicts=1to force eMake to honor directory-read conflicts for the build. -
Use the
#pragma readdirconflictspragma to enable directory-read conflicts on a per-job basis. You can apply it to targets or rules in your makefiles. This pragma has less overhead than--emake-readdir-conflicts=1(which enables directory-read conflicts for an entire build). You can use this pragma in pragma addendum files as well as in standard makefiles.