|
This is Rollout-legacy documentation. For Rollout customers: This (Rollout) documentation remains available through your end-of-service date. CloudBees Feature Management is now part of CloudBees Unify. Refer to CloudBees Unify Feature management documentation. |
|
Experiments have been deprecated and Flags are the only entity in the system.
|
CloudBees Feature Management leverages GitHub apps to allow integration and minimize access. CloudBees Feature Management only accesses the repository that contains the CloudBees Feature Management data.
To activate Configuration as Code (CasC) with GitHub:
-
Create an empty repository on GitHub.
-
Connect CloudBees Feature Management to the GitHub repository as follows:
-
From the CloudBees Feature Management Home page, from the left navigation pane, select App Settings, and then select the Integrations tab.
-
Navigate to the Configuration as Code: GitHub pane, and then select Connect.
 Figure 1. The GitHub Connect highlighted
Figure 1. The GitHub Connect highlighted -
-
In GitHub, select to integrate the CloudBees Feature Management GitHub app with your created repository.
 Figure 2. Integrating with GitHub
Figure 2. Integrating with GitHub -
After selecting Install, you are redirected back to CloudBees Feature Management to select your app and the repository.
 Figure 3. Connecting to GitHub
Figure 3. Connecting to GitHub -
Select Connect.
CasC with GitHub is activated within CloudBees Feature Management.
Connecting to GitHub Enterprise
To enable the connection of CloudBees Feature Management to GitHub Enterprise, you must first create a GitHub application that allows CloudBees Feature Management to connect to it.
Select Need our help? from the bottom of any screen within CloudBees Feature Management to request a walkthrough session.
Repository, directories, and YAML structure
Branches are environments
Every environment within CloudBees Feature Management is mapped to a
branch in Git. The same name used for the environment is
used for the branch name. The only exception is the Production
environment, which is mapped to the master branch.
CloudBees only supports master as the branch name for the Production environment. You cannot use main as the branch name.
|
The |
Directory structure
The repository integration creates the following directory structure:
. ├── experiments # Experiments definitions │ └── archived # Archived experiments definitions ├── target_groups # Target groups definitions └── README.md
-
All Experiments are located under the Experiment folder
-
All archived Experiments are located under the
experiments/archivedfolder
Experiment examples
Example: False for all users
flag: default.followingView type: experiment name: following view value: false

Example: 50% split
flag: default.followingView type: experiment name: following view value: - option: true percentage: 50

Example: Feature only available to QA or beta users who are using version 3.0.1
flag: default.followingView type: experiment name: following view conditions: - group: name: - QA - Beta Users version: operator: semver-gte semver: 3.0.1 value: true value: false

Example: Feature available for all platforms, except for Python
For more information, refer to Multiplatform feature flags.
flag: default.followingView type: experiment name: following view platforms: - name: Python value: false value: true
")
")
Experiment YAML
This section describes the YAML scheme for an Experiment. It is a composite of 3 schemas:
-
Root schema - the base schema for experiment
-
Split value schema - Represents a split value - a value that is distributed among different instances based on percentage
-
Scheduled value schema - Represents a scheduled value - a value that is based on the time that the flag was evaluated
-
Condition schema - Specify how to target a specific audience/device
-
Platform schema - Specify how to target a specific platform
Root schema
An Experiment controls the flag value in runtime:
# Yaml api version # Optional: defaults to "1.0.0" apiVersion: Semver # Yaml Type (required) type: "experiment" # The flag being controlled by this experiment (required) flag: String # The available values that this flag can be # Optional=[false, true] availableValues: [String|Bool] # The name of the experiment # Optional: default flag name name: String # The Description of the experiment # Optional="" description: String # Indicates if the experiment is active # Optional=true enabled: Boolean # Expriment lables # Optional=[] labels: [String]|String # Stickiness property that controls percentage based tossing # Optional="rox.distict_id" stickinessProperty: String # Platform explicit targeting # Optional=[] platforms: [Platform] # see Platform schema # Condition and values for default platform # Optional=[] conditions: [Condition] # see Condition schema # Value when no Condition is met # Optional # false for boolean flags # null for enum flags (indicates default value) value: String|Boolean|[SplitedValue]|[ScheduledValue]
Scheduled value is only supported for boolean flags
Scheduled Value is supported only for boolean flags, you can’t use them for Variant flags.
Condition schema
The Condition is a pair of condition and value, an array of conditions can be viewed as an if-else statement by the order of conditions.
The schema contains three types of condition statements.
-
Dependency - express flag dependencies, by indicating flag name and expected value
-
Groups - a list of target-groups and the operator that indicates the relationship between them (
or|and|not) -
Property - a single property, the operator and operand (very similar to Target groups' condition); can also include multiple conditions (see multiple property conditions)
-
Version - comparing the version of
Select either Flag Dependency, Target Group, or Property
The relationship between these items can be either and or or between all conditions, meaning:
If the dependency is met and Groups matches and Property matches and Version matches then flag=value
or
If the dependency is met or Groups matches or Property matches or Version matches then flag=value
Here is the Condition schema:
# Condition this flag value with another flag value dependency: # Flag Name flag: String # The expected Flag Value value: String|Boolean # Condition flag value based on target group(s) group: # The logical relationship between the groups # Optional = or operator: or|and|not # Name of target groups name: [String]|String # Condition flag value based on a single property property: # The Custom property Name to be conditioned name: String # The Operator of the confition operator: is-undefined|is-true|is-false|in-array|eq|ne|gte|gt|lt|lte|regex|semver-ne|semver-eq|semver-gte|semver-gt|semver-lt|semver-lte # The Second operand of the condition # Optional - Based on operator (is-undefined, is-true, is-false) operand: String|Number|[String] # Condition flag value based on a multiple property conditions (alternative to the above) property: # All property conditions (same structure as target group's conditions. see Target Group's schema conditions) propertyConditions: # The Custom property Name to be conditioned - property: String # The Operator of the confition operator: is-undefined|is-true|is-false|in-array|eq|ne|gte|gt|lt|lte|regex|semver-ne|semver-eq|semver-gte|semver-gt|semver-lt|semver-lte # The Second operand of the condition # Optional - Based on operator (is-undefined, is-true, is-false) operand: String|Number|[String] # Condition flag value based release version version: # The operator to compare version operator: semver-gt|semver-gte|semver-eq|semver-ne|semver-lt|semver-lte # The version to compare to semver: Semver # The logic gate between conditions acrossTypesLogicGate: or|and # Value when Condition is met value: String|Boolean|[SplitedValue]|[ScheduledValue]
Platform schema
The platform object indicates a specific targeting for a specific platform.
# Name of the platform, as defined in the SDK running name: String # Override the flag name, when needed # Optional = experiment flag name flag: String # Condition and values for default platform # Optional=[] conditions: [Condition] # see Condition schema # Value when no Condition is met # Optional # false for boolean flags # null for enum flags (indicates default value) value: String|Boolean|[SplitedValue]|[ScheduledValue] # see Value schema
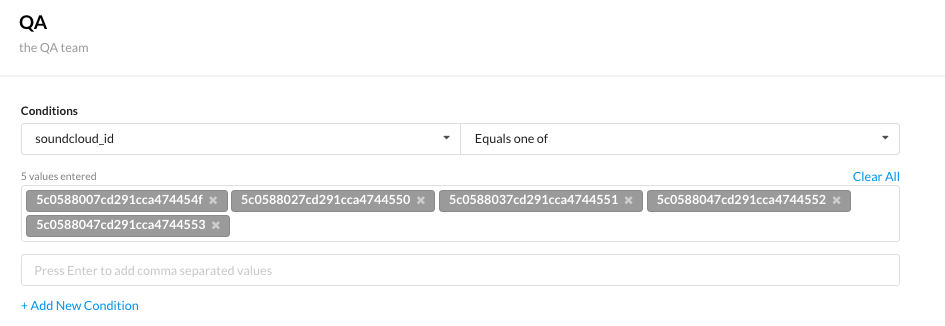
Using number property for comparison
type: target-group name: DJ operator: or conditions: - operator: gte property: playlist_count operand: 100 description: Users with a lot of playlists
In the UI:
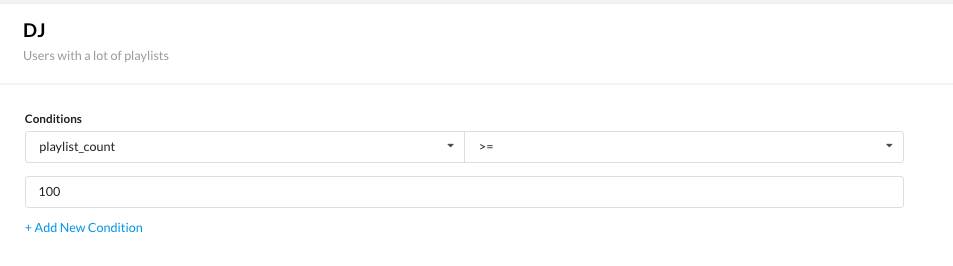
Target Group YAML
A Target group is a set of rules on top of custom properties that are defined in runtime, it is used in experiment conditions.
# Yaml api version # Optional: defaults to "1.0.0" version: Semver # Yaml Type (required) type: "target-group" #Target Group Name name: String # Target Group description # Optional = "" description: String # The logical relationship between conditions # Optional = and operator: or|and # Array of Conditions that have a logical AND relationship between them conditions: # The Custom property to be conditioned (first operand) - property: String # The Operator of the confition operator: is-undefined|is-true|is-false|in-array|eq|ne|gte|gt|lt|lte|regex|semver-ne|semver-eq|semver-gte|semver-gt|semver-lt|semver-lte # The Second operand of the condition # Optional - Based on operator (is-undefined, is-true, is-false) operand: String|Number|[String]