CloudBees Flow supports enterprise-scale software production. Based on a three-tier architecture, CloudBees Flow scales to handle large, complex environments. CloudBees Flow’s multithreaded Java server provides efficient synchronization even under high job volume.
Local Configuration
The following diagram shows a CloudBees Flow architecture configuration at a single site.
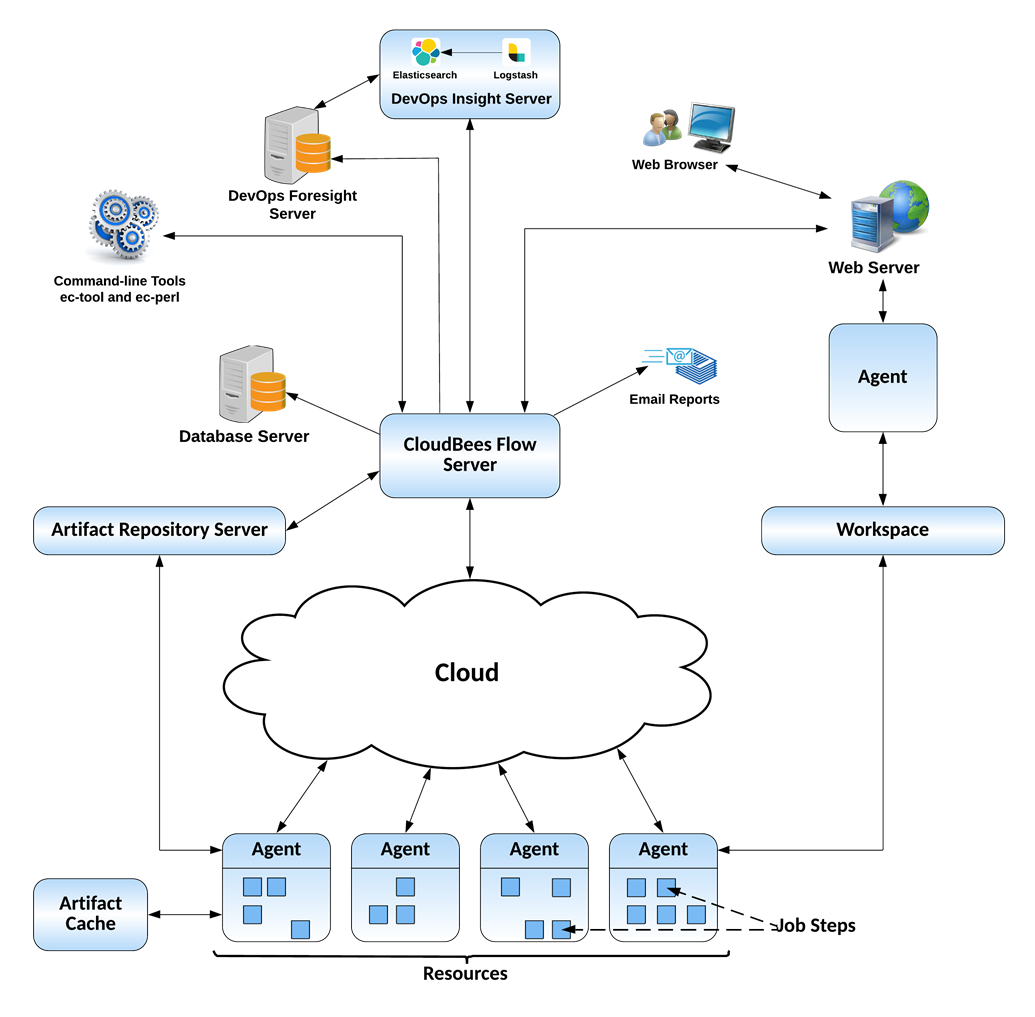
In the local configuration:
-
The CloudBees Flow server manages resources, issues commands, generates reports.
-
An underlying database stores commands and metadata.
-
Agents execute commands, monitor status, and collect results, in parallel across a cluster of servers for rapid throughput.
Remote Database Configuration
For a production environment, CloudBees recommends that you install the database on a separate machine from the CloudBees Flow server to prevent performance issues. It is acceptable for the CloudBees Flow server, web server, and repository server to reside on the same machine in a local configuration, but not required. If you are only evaluating CloudBees Flow, CloudBees Flow, the database, the CloudBees Flow server, the web server, and the repository server can reside on the same machine.
Remote DevOps Insight Server Configuration
For a production environment, CloudBees recommends that you install the DevOps Insight server on a system other than systems running other CloudBees Flow components (such as the CloudBees Flow server, web server, repository server, or agent). If you must install it on the same system (such as for testing or other nonproduction or trial-basis situations only), see Running on a system with Flow components for instructions.
Remote Web Server Configuration
The following diagram shows an example of a remote web server architecture configuration.
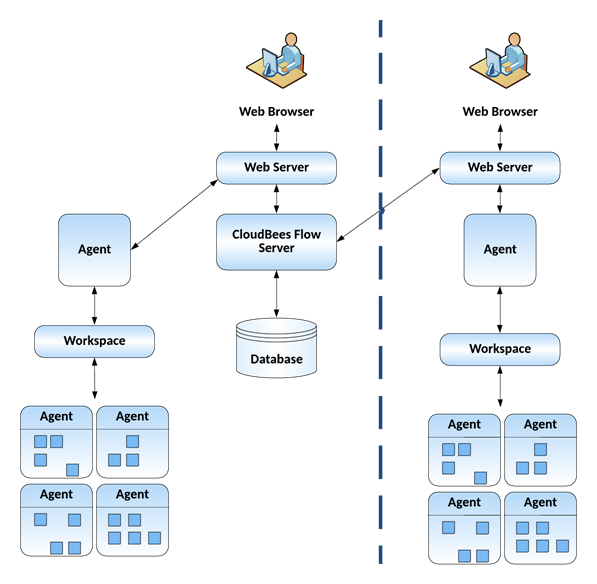
In this example remote web server configuration:
-
There are web servers at each site
-
The database and CloudBees Flow server is located at your headquarters
-
Proxy resources exist at each site
Benefits of a Remote Web Server Configuration
A remote web server configuration helps prevent network latency. If you have multiple sites, CloudBees Flow can be configured in numerous ways to help you work more efficiently.
Central Web Server and a Remote Web Server at Each Site
You should consider installing multiple web servers for different locations in your organization to help handle user web traffic . CloudBees Flow supports multiple workspaces, including those co-located on agents that use them. In this architecture, step log files are created locally so even the largest log files can be captured without a performance penalty.
You can view the step log files remotely from the web UI, but performance decreases if the files must be retrieved across the WAN. This means that remote users will experience the penalty when the web server retrieves the step log file contents and when the contents are sent back across the WAN to the browser.
To minimize these performance issues, install one central CloudBees Flow server, and then install a CloudBees Flow web server at each remote site. The remote web servers should be co-located with the remote agents and workspaces so remote users can log in through their local web server. Any operations initiated from the remote location, including running jobs, are completed by the central CloudBees Flow server.
In this configuration, job data is retrieved from the central server when a remote user views the Job Details page. If the job is using a workspace at the remote user’s site, the links to all step log files will refer to local paths.
Also, in this configuration, the log files are accessed only by the remote web server’s agent and not the CloudBees Flow server. This eliminates both trips across the WAN, which improves performance. The CloudBees Flow web server reads the log file locally (via its local agent) and then displays the page to the user whose browser is also on the same side of the WAN.
Prerequisites for Installing Remote Web Servers
For details about the remote web server prerequisites such as memory, agents, and centralized plugin directory access, see Remote Web Server Installation Prerequisites .
Clustered Configuration
The following diagram shows a CloudBees Flow clustered configuration.
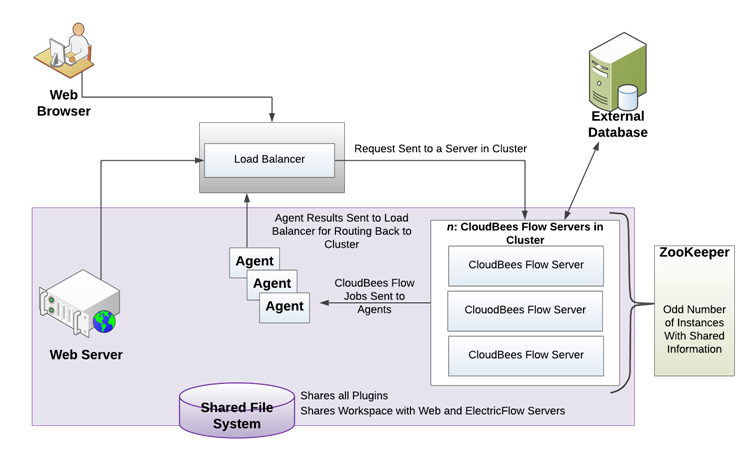
You can also add horizontal scalability and high availability to your CloudBees Flow environment by adding additional machines to create a clustered CloudBees Flow configuration.
Benefits of a Clustered Configuration
A clustered CloudBees Flow configuration has the following benefits:
-
Add fault tolerance by re-routing jobs to running CloudBees Flow servers
-
Increase the supported number of simultaneous jobs and corresponding API requests
-
Expand capacity over time by adding additional CloudBees Flow servers
-
Distribute API requests across multiple CloudBees Flow servers
-
Distribute CloudBees Flow requests across multiple web servers
Required Additional Software Components for Clustered Machines
A clustered CloudBees Flow configuration requires two additional software components:
-
A centralized service for maintaining and synchronizing group services in cluster
-
A load balancer for routing work to machines in the cluster
Plugins Directory Accessibility Requirement for Clustered Machines
CloudBees strongly recommends that all server machines in a clustered server configuration be able to access a common plugins directory. This avoids the overhead of managing multiple plugins directories. For details, see Configuring Universal Access for a Network Location .
See Clustering for additional details and clustered configuration set up procedures.