Types of Tasks
-
Application or microservice process : Use this to deploy applications or microservices at the right time in a pipeline. For an example of how to deploy applications or microservices, see Deploying and Troubleshooting Applications .
When artifact staging is enabled for an application, CloudBees Flow tries to retrieve artifacts that will be deployed before the application run starts. This ensures that the artifacts are downloaded and available on the target (either the artifact cache (the default) or a directory specified in the component definition). This minimizes the time to retrieve artifacts and reduces downtime during the application deployment.
-
Deployer : This is a special type of task used when you want to deploy applications or microservices in a release but will provide the details in the release definition. When using deployer tasks, the system automatically knows the applications or microservices to deploy, which are provided as part of a release definition instead of separate deploy tasks for each application or microservice. For details, see Release Management. You can use one or more deployer tasks per stage.
-
Procedure : Use this to run a set of best practices, subroutines, modules, or functions that you can create and reuse at the platform level. Examples are scripts, command sets, or other automation logic objects. You specify the procedure name directly or dynamically using the property reference notation,
$[]. For example,$[/myPipeline/procedure_to_run], where procedure_to_run is a property in the pipeline with procedure name in value.For details, see Pipeline Task Definitions . -
Manual : Use this when a task should be performed manually. The appropriate notifications are sent to the user or group who performs that task and to the user or group who responds when the task is completed. For more information about completing a manual task and restarting its pipeline, see Example: Visibility in a Release Pipeline from the Release Dashboard .Command: Use this to add command-based steps. This lets you perform command scripting as part of the orchestration.
-
Command : Use this to add command-based steps. This lets you perform command scripting as part of the orchestration.
-
Workflow : Use this to run a set of procedures in CI life cycles at the platform level. A workflow can combine all procedures for a build-test-deploy life cycle. For details, see Workflow Overview.
After the workflow is completed, it returns the workflow state to the pipeline as
ERRORorSUCCESS:ERROR: This means that theERROR_LOGhas entries,/myWorkflow/outcomeor/myWorkflow/resultiserror, the workflow ended in a state that includes Error or Fail in its name, or it has any failed jobs.SUCCESS:/myWorkflow/outcomeor/myWorkflow/resultexist and are not equal toerror. -
Plugin : Use this to run third-party procedures that interface with external systems. Plugin tasks let you integrate and orchestrate third-party tools. For example, you can run Selenium automation at the right time by using the Selenium plugin. For details about plugin tasks, see Plugin Pipeline Tasks .
-
Utility : Use this to run a utility function, which is a higher-order operation than a third-party plugin, as a stage task. You can also define an application process step, service process step, or component process step as a utility function. For information about defining an application, service, or component process step as a utility function, see Authoring Application Processes or Authoring Component Processes .
-
Pipeline : Use this to trigger another pipeline to run, either synchronously or asynchronously (default). See Pipeline Hierarchies.
-
In a pipeline context: By default, the name of the pipeline you configure for this type of task surfaces in the release portfolio when the pipeline is triggered. In order to distinguish the specific pipeline instance, define a custom pipeline name that gives local context in the Custom Pipeline Label field of the task definition dialog. Specify a string or a reference to a definition or runtime object. Maximum of 255 characters.
-
-
Release : Use this to trigger another pipeline to run in a release context, referred to as a sub-release, either synchronously or asynchronously (default). See Pipeline Hierarchies.
-
In a release context: By default, the name of the release you configure for this type of pipeline task surfaces in the release portfolio when the release is triggered. In order to distinguish the specific release instance, define a custom release name that gives local context in the Custom Release Label field of the task definition dialog. Specify a string or a reference to a definition or runtime object. Maximum of 255 characters.su
-
Task Skipping
You can skip specific tasks at runtime by using the Enabled check box for those tasks in a task list. This check box is checked by default.
Configuring Pre-Run Tasks
Tasks can be configured to run out of order; tasks so configured are referred to as pre-run tasks. When envoked at pipeline runtime, only the specified task is run; execution does not continue to following tasks and stages. When pipeline run execution reaches a task which has already run, the pre-run task is skipped. If the pre-run task is still running, then the pipeline execution waits for it to complete and then continues on to the following tasks. See Pre-running a Task for more runtime details.
To configure a task to run out of order:
-
Select Details from the task’s Actions menu. The Edit Task dialog appears.
-
Select the Pre Run check box and then its Open Dialog button to define users having access to pre run the task.
Parallel or Serial Tasks
All tasks, including manual tasks, can be run in serial, in parallel, or in a combination of both. By default, tasks in a pipeline stage or within a deployer task run serially in the order in which they were defined. In complex application or microservice processes with numerous pre- and post-deployment tasks, sometimes tasks without dependencies should be run in parallel to reduce runtimes.
Parallelizing tasks shortens the time to complete a stage or deployment. In a short deployment window to complete large numbers of deployments, this feature can dramatically impact how many deployments can be completed in that window. For example, in a stage with two manual tasks, each of which requires a separate user to perform actions that do not depend on the other user, these tasks can run at the same time. For a release with 80 applications or microservices, in which each one has two manual tasks to prompt users, and each user response takes 15 minutes, the total wait time for these tasks is 40 hours with serial tasks and 20 hours with parallel tasks.
For information about creating parallel tasks, see Running Pipeline Tasks in Parallel .
Multiple Deployers
Using more than one deployer task in a pipeline stage lets you deploy applications or microservices in parallel rather than in series. This lets you control deployer behavior depending on the applications or microservices to be deployed. This feature is useful for complex releases where you must coordinate the release of applications or microservices. Multiple deployers provide the flexibility to run other types of tasks between deployments such as infrastructure configuration tasks.
Following are examples of how multiple deployers are used:
-
A release has ten applications. The first four are infrastructure applications (RPMs) that must run. After deployment of these four applications, a test is run to confirm successful infrastructure deployment. The remaining six applications can then be deployed.
-
A release has ten microservices. Microservices one through five can run in parallel, and microservices six through ten can run in parallel, but six through ten have a dependency that one through five must be installed first. The microservices can be broken into two deployers that run serially with microservice deployments within them that run in parallel.
How Release Mappings Determine Multiple Deployer Behavior
If a deployer has a mapping to a release, then it deploys applications based only on that release application mapping. If it does not have a mapping, then it deploys all applications that are part of the release configuration.
Simple Use Case
Let’s say you have two deployers, and neither deployer is mapped to a release. In this case, both deployers will deploy all applications.
Complex Use Case
Let’s say that a release has three applications:
-
Application1
-
Application2
-
Application3
And that the release contains a pipeline stage with deployers as follows:
-
Deployer1—serial
-
Deployer2—expression (take all applications from the project)
-
Deployer3—parallel
And that the release has the following configuration:
-
Application1 → Deployer3
-
Application2 → Deployer3
-
Application3 → Deployer3
Then the applications will be deployed as follows:
-
Deployer1 deploys all applications (because there is no explicit mapping for Deployer1).
-
Deployer2 deploys any applications that meet the expression criteria.
-
Deployer3 deploys Application1, Application2, and Application3 (because a user-defined mapping exists for Deployer3 to Application1, Application2, and Application3).
Error Handling Behavior for Deployer Tasks Running in Parallel in a Group
Following are a few scenarios and their behaviors :
| Scenario | Outcome |
|---|---|
The deployer task has |
All deployer tasks in the group are aborted, and the next task (if any) is activated. |
The deployer task has |
Other deployer applications continue to run. It has no impact on other deployer tasks in the group. |
The deployer task has |
The applications continue to run. If any of them fails, the deployer task aborts other deployer tasks in the group once all applications are completed. |
The deployer task has |
If the application with |
The deployer task has |
If an application fails, the deployer task aborts all applications in the current deployer task and other deployer tasks in the group. |
The deployer task has |
If any application fails, the remaining applications in the deployer task are aborted, but other deployer tasks are not impacted. |
By default, all group tasks (including deployer group tasks) use `stopOnError` error handling.
Restarting Deployer Tasks
This section describes the various cases for restarting parallel and serial deployer tasks and groups with different error handling.
stopOnError Error Handling
-
When you restart a parallel deployer task or group, CloudBees Flow restarts the entire deployer task or group.
-
When you restart a serial deployer task or group, CloudBees Flow restarts the run from the deployer task containing the failed deployer applicati on or from the failed subtask in the group.
Error Handling
When defining a task or a group of parallel or serial tasks, you must specify whether the pipeline continues or stops if the task or task group fails because of an error. To do so, you must select either Continue on Error, Stop on Error, or (additionally for pipeline tasks except manual and group tasks), Manual Retry on Error or Automated Retry on Error.
Manual Retry on Error or Automated Retry on Error let you enable a retry capability to rerun specific pipeline tasks that have failed. For example, if a hard drive fills up and causes a pipeline failure during tests near the end of that pipeline, you do not need to rerun the entire pipeline.
Following are the available error handling choices for tasks and serial or parallel task groups.
| Error Handling | Available in Individual Non-Manual) Tasks? | Available in Manual Tasks? | Available in Parallel Group Tasks? | Available in Serial Group Tasks? | Description |
|---|---|---|---|---|---|
Continue on Error |
Yes |
Yes |
Yes |
Yes |
If any task fails or is rejected, the pipeline will still continue, allowing any other parallel tasks to complete before moving onto the next stage task or gate. |
Stop on Error |
Yes |
Yes |
Yes |
Yes |
If any task fails, the pipeline aborts. This is the default behavior. This behavior is usually used in Continuous Delivery pipelines. |
Manual Retry on Error |
Yes |
No |
Yes |
Yes |
An approver or assignee reviews the error and retries, skips, or fails the task. The test failure is caught (and the name of the task turns red to indicate the failure). Then, the pipeline prompts an operator with |
Automated Retry on Error |
Yes |
No |
Yes |
Yes |
The task is automatically retried at specific time intervals for a specific number of times, after which you can specify whether the pipeline stops or continues. |
Always-Run Capability for Tasks and Task Groups
You can define an “always run” task, which runs regardless of the error handling behavior for preceding tasks. This capability is most commonly used for cleanup operations at the end of a stage or gate.
You can also define an “always run” task group. Enabling this option guarantees that the tasks will run before the pipeline execution ends. Note that if this option is selected, and any individual task in the group that has error handling set to Stop on Error fails, then all the running tasks will be aborted.
Restart Failed Pipeline Runs
A restart capability for failed pipeline runs lets you configure a pipeline run to restart from the last failed task after you update the task definition and fix the issues that caused the failure.
A pipeline run is restartable if the last executed task in the run failed. If it is also the last task in a stage or gate, then its error handling must not be Continue on Error. Any prior failed tasks, in the same or previous stages or gates, with Continue on Error error handling enabled are ignored.
Restarting a Pipeline from Any Stage Without a New Run
You can restart pipelines from any stage or task for better control when recovering from failures. This provides finer control to determine exactly which set of tasks needs to be restarted and from where, while maintaining the context of the entire pipeline. The pipeline view lets you easily see all runs of stages and tasks for visibility into the entire process.
This feature lets you restart the same pipeline run from any previously run stage rather than creating a new run. The previous run could have completed successfully, failed, or could be still active (such as when it is waiting on a manual task).
This feature includes the ability to restart a pipeline from the point of failure manually or automatically at a point earlier than the failure point. This lets you restart an entire stage using the parameter values and output properties from the prior stages in the pipeline to maintain the context of the entire pipeline run. This functionality provides a single view for all runs if you have multiple runs for each stage, so that you do not need to know the specific runs where a stage was successful.
Usage Scenarios
Following are a couple of examples that illustrate the benefits of this feature:
-
In a pipeline with Dev, QA, and Prod stages, the fourth task on the QA stage failed: you could restart the same pipeline run from that task. This feature extends this capability by letting you restart the run from the beginning of the QA stage, for example. This means that you need not create a new pipeline run from the QA stage, which avoids losing the parameter values and other runtime context from the earlier run.
-
Let’s say you have a pipeline for mainframe automation with Stage, UAT, Pre, Blue, and Prod stages, and each stage contains tasks. When the pipeline starts, user inputs are gathered via parameters.
The UAT stage contains the first few tasks that drive automation in ISPW such as Promote the Release, Get Information from ISPW, and Create Evidence Report. After those tasks, a manual task in UAT seeks manual approval to go forward. In some cases, when a pipeline run reaches the approval task in UAT, the approver might notice several details to be tweaked on the ISPW side before the pipeline can proceed. But when those details are tweaked in ISPW, the entire UAT stage must be rerun without losing the context of all input parameters and so on until the UAT stage begins.
Stage Restart Details
-
If at restart time, the previous run for the stage is still active, then all running tasks are aborted, and remaining tasks are skipped.
-
When you restart a pipeline run from a specific stage, CloudBees Flow injects a new stage between the failed stage and the next stage (and leaves the failed task as-is for your examination later). This lets you view the new run as well as all previous runs. Every new run for the stage or task will be identified with a new run number.
-
When multiple runs exist for a stage, the context-relative property reference always looks up the properties (such as
/myPipelineRuntime/QA_stage/prop1) on the latest run. -
The stage count and progress percentage computation are based on the latest stage runs.
Task Restart Details
-
As with the stage restart functionality described above, instead of resetting and rerunning the failed task, CloudBees Flow injects a new task (with the same name) between that task and the next task.
-
Restarting a pipeline from a failed task is as described in Restart Failed Pipeline Runs .
-
The restart behavior for group tasks is as follows:
-
Restart the entire task group if the task is parallel.
-
Restart from any task in the group, if the task group is serial.
For more information, see Error Handling .
-
Pipeline Restart Options
You can choose from the following main options for a pipeline restart:
| Restart Option | Restrictions | API Command | Result |
|---|---|---|---|
Restart a pipeline from a failed task |
This is for failed pipeline runtimes only. It does not apply if the last completed task did not fail (when the failed task has |
|
|
Restart a pipeline from a specific task |
This is only for active stages or gates (for running pipelines) or last completed stages or gates (for failed pipelines). You cannot restart from a task that was not started yet. |
|
If the pipeline is running, the active task is aborted first, and then the following restart logic is used:
|
Restart a pipeline from a specific stage |
You cannot restart from a stage that has not run yet. |
|
If the pipeline is running, the active stage is aborted first, and then the following restart logic is used: For each stage from the specified one and to the last completed one, new flow run-time states ( |
Assigning a Resource or Pool to a Stage or Task for Commands, Procedures, or Plugins
By default, pipeline command, procedure, or plugin tasks run in the default pool or under a resource or pool specified within the runCommand procedure in the EC-Core plugin. You can specify a resource or pool for these types of tasks to execute on. You can also make this selection at the stage level, which will apply to all applicable tasks unless overridden there. This feature lets you run tasks on specific deployment environments.
Pipeline Hierarchies
A pipeline hierarchy is comprised of triggering and dependent pipelines. Consider an organization having pipelines that are dependent on each other at different stages. These pipelines deploy into shared environments, some stages may actually provision environments used by the release or other releases. So if a stage misses its deadline it can cause a cascading effect delaying other releases. Pipeline hierarchies provide a way to organize pipelines in order to minimize risks, bottlenecks, and delays in the release.
When defining pipeline and release tasks, you can:
-
Create a task that triggers a dependent pipeline, either directly or in a release context.
-
Run the dependent pipeline synchronously or asynchronously.
-
Configure the behavior of the triggering pipeline run when the dependent pipeline fails (error handling).
-
Configure a stage, task, or gate of the triggering pipeline to wait for the triggered dependent pipeline or additional, non-triggered pipelines to complete before it runs.
Setting up a Pipeline Hierarchy
-
For each triggering task: set task type to either Pipeline or Release at task definition time, based on the runtime context of the triggered pipeline—either outside of a release or in a release context, respectively.
-
Specify a custom pipeline label for pipeline tasks: the name of the pipeline at task definition time surfaces in the pipeline or release portfolio when the pipeline is triggered. In order to distinguish the specific pipeline instance, define a custom pipeline name that gives local context in the Customize Pipeline Label field of the task definition dialog. Specify a string or a reference to a definition or runtime object. Maximum of 255 characters.
-
Specify the triggering pipeline behavior in the event of a error or rejection by the triggered pipeline .
-
Specify how triggering pipeline is run: asynchronously or synchronously.
-
-
For each pipeline object: set wait conditions. See Wait Dependencies for details.
Pipeline Hierarchy Example
Consider three pipeline definitions A, B, and C, each with DEV, QA, and PROD stages.
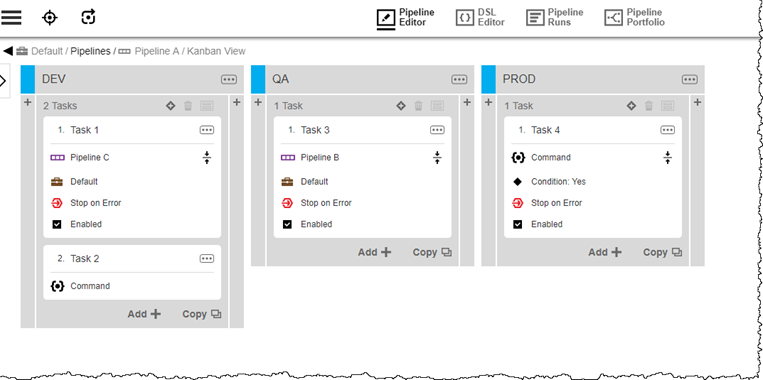
Pipeline A:
-
DEV Task 1 is a pipeline task that triggers Pipeline C, configured to run synchronously.
-
QA Task 3 is a pipeline task that triggers Pipeline B, configured to run synchronously.
-
Stage DEV sets Wait for all triggered pipelines.
-
Triggered pipelines B and C run in Pipeline A’s runtime context. Other instances of triggered pipelines B and C run in the context of their triggering pipeline.
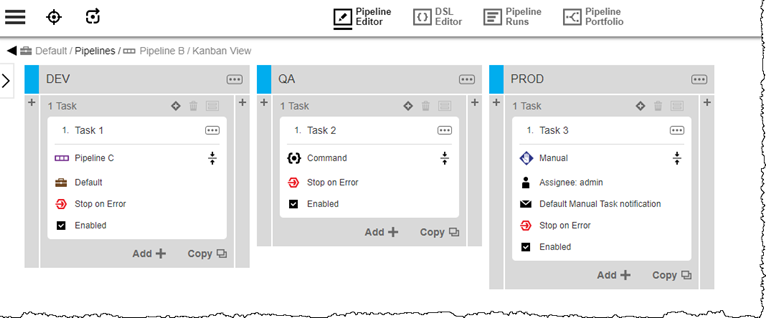
Pipeline B:
-
DEV Task 1 is a pipeline task that triggers Pipeline C, configured to run synchronously.
-
Stage DEV sets Wait for all triggered pipelines.
-
PROD Task 3 is a manual task: it requires manual intervention to complete. Any upstream triggering pipeline is blocked until the task is marked as complete.
-
Triggered Pipeline C runs in Pipeline B’s context. Other instances of triggered Pipeline C run in the context of their triggering pipeline.
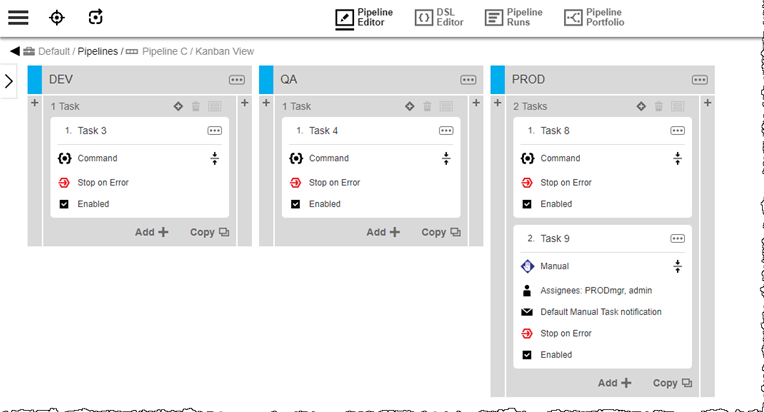
Pipeline C:
-
PROD Task 9 is a manual task: it requires manual intervention to complete. Any upstream triggering pipeline is blocked until the task is marked as complete.
-
Triggered Pipeline C runs in the context of its triggering pipeline.
Using the above pipeline definitions, consider the two separate hierarchies as follows:
-
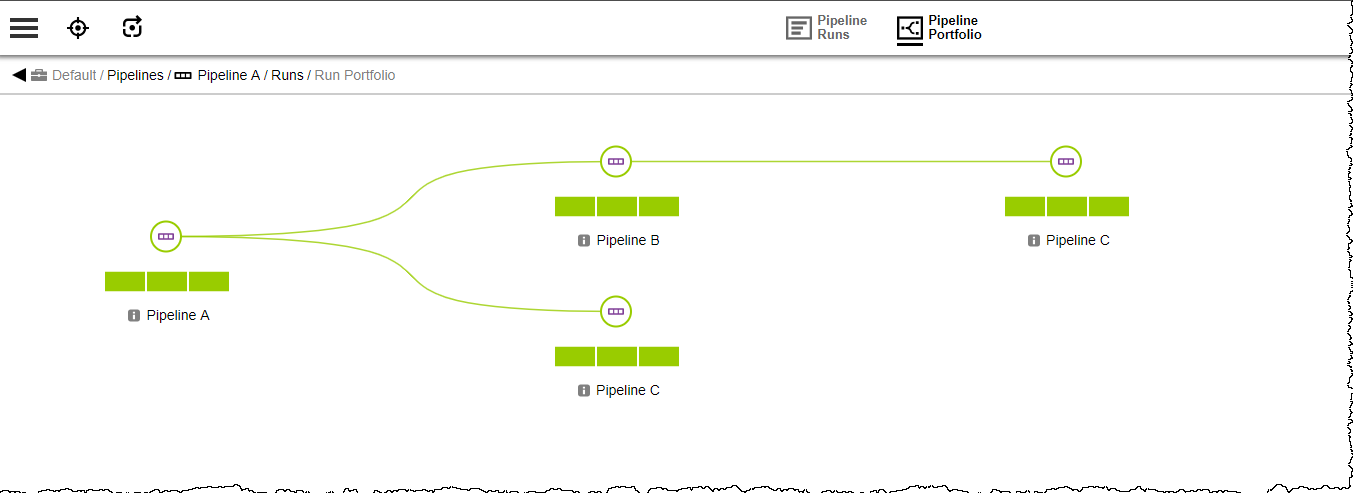
Hierarchy 1: Pipeline B Stage DEV Task 1 triggers Pipeline C. Pipeline Portfolio view:
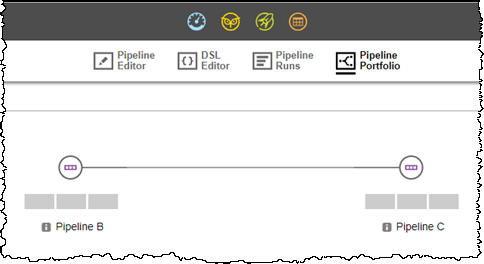
-
Hierarchy 2: Pipeline A Stage DEV Task 1 triggers Pipeline C and Stage QA Task 3 triggers Pipeline B. Because Pipeline B is triggered, this hierarchy inherits hierarchy 1. However, the runtime context for pipelines B and C is separate from the context in hierarchy 1. Pipeline Portfolio view:
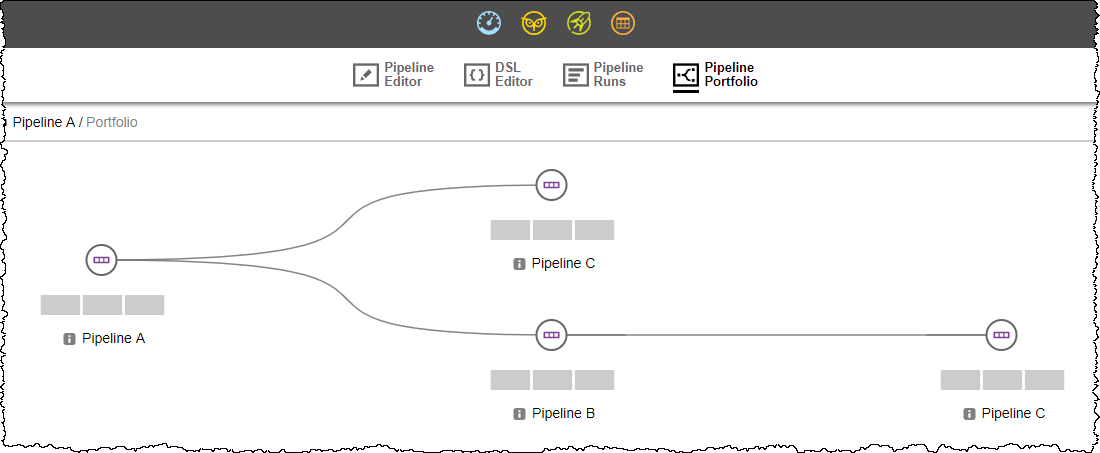
Running the Hierarchy
Pipeline B run is initiated to start Hierarchy 1. After the run starts, look at the Pipeline Portfolio for this run to get status:
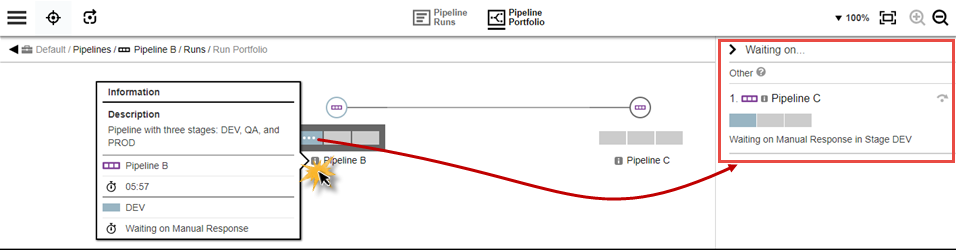
-
Click the
 for Pipeline B to see information about this pipeline.
for Pipeline B to see information about this pipeline. -
Click the
 that represents the first stage for Pipeline B: this opens a status panel on the right. In this instance, you can see that this stage is waiting on a manual response from Pipeline C.
that represents the first stage for Pipeline B: this opens a status panel on the right. In this instance, you can see that this stage is waiting on a manual response from Pipeline C.
Looking at the current run instance for Pipeline C (Pipeline C_17_20181108145753) on the Pipeline Runs page, Task 9 in Stage PROD is pending manual confirmation.
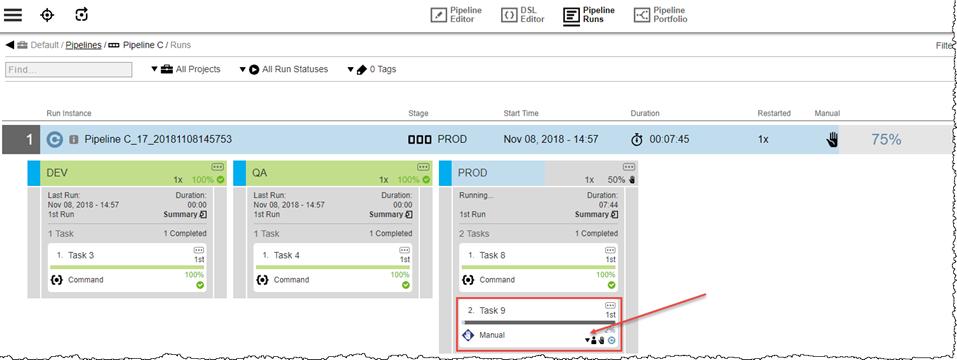
Now, Pipeline A run is initiated to start Hierarchy 2. It triggers Pipeline C (Pipeline C_18_20181108151821), which is a different runtime instance than that for Hierarchy 1.
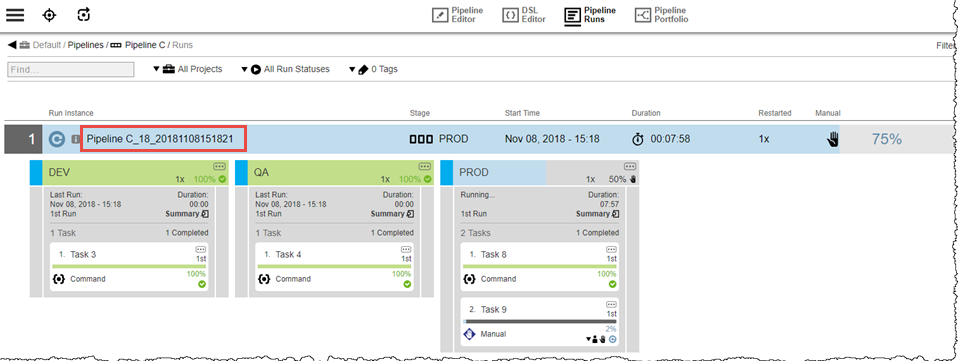
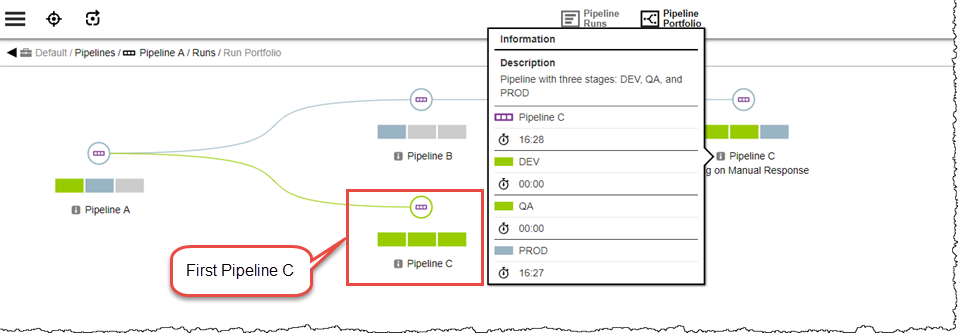
After the manual approval is completed for Pipeline C Stage PROD Task 9, Pipeline A triggers Pipeline B, which in turn triggers Pipeline C. And again, the hierarchy is pending on Pipeline C Stage PROD Task 9. Notice the first Pipeline C is complete.
The run progresses to Pipeline B Stage PROD, where another manual task is encountered.
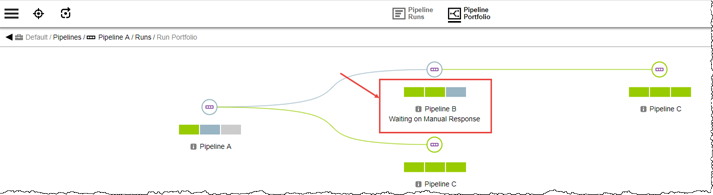
After the manual approval is completed for Pipeline B Stage PROD, the hierarchy completes, as can be seen in the following image:ROOT: all stages are now green.