Use this page for quick access to configuring resources, workspaces, email configurations, your source control system, and defect tracking to communicate with CloudBees Flow.
| If you are viewing this Help topic from the "Configuring CloudBees Flow" web page, use these instructions: |
Click the Add link for any object you want to configure and that objects configuration page is displayed.
-
Each item you configure will be listed in this table for your easy reference.
-
Configure objects listed in this table are linked to their respective "Edit…" page in the event you need to modify any values previously supplied. Select a configured object to edit its values.
The table below provides a brief description of CloudBees Flow configuration tasks.
Before resources can be set up, you need to know which agent machines are available to allocate to jobs. The CloudBees Flow Resource web page displays all resources currently available to the CloudBees Flow server. This section also describes how to run the resource scheduler in multiple threads to parallelize scheduling, which potentially increases scheduler throughput (and thus overall CloudBees Flow server throughput). |
|
CloudBees Flow provides each job step with an area on the disk it can use for "working files" and results. This disk area is called a job workspace . A job step can create whatever files it needs within its workspace and CloudBees Flow automatically places files, such as step logs, in the workspace. The location of the job step workspace is displayed on the Job Details web page. |
|
If you do not create an Email Configuration, you will be unable to send email notifications to individuals or groups. If you have multiple users or groups in remote locations who use a different mail server, you will want to create additional email configurations to accommodate those locations if they need to receive notifications. |
|
CloudBees Flow needs to communicate with your Source Control system (SCM) if you intend to use the CI Dashboard for continuous integration schedules to start a new build based on new/modified source control checkins, or if you plan to configure Preflight builds (to build and test code changes before those changes are "committed"). |
|
CloudBees Flow uses account information from multiple sources. In most cases, the primary account information source is an external LDAP or Active Directory repository: both user and group information is retrieved from the repository. Local users and groups can be defined within CloudBees Flow. |
|
Setting Up Defect Tracking |
CloudBees Flow uses plugins to integrate with numerous defect tracking systems. If the plugin you need for your defect tracking system is not automatically installed with CloudBees Flow, see the Plugin Catalog to find the integration you need. |
Using the Web Server Host server setting ensures correct URLs in email notifications from the CloudBees Flow server if the Apache web server name differs from the CloudBees Flow server name. For example, if the servers are on separate machines. |
Web Interface Online Help System
Use the automation platform online Help system for more information. Click the Help link in the top-right corner of any product web page to see a specific Help topic for that page.
When the Help system opens, we recommend reviewing the Help table of contents. All Help folders above the Web Interface Help folder are user-guide style Help topics that provide more detailed information on each of their topics. If you generally prefer to use a command line rather than the CloudBees Flow web interface, you will find complete ectool (the CloudBees Flow command-line tool) commands and arguments here too.
Setting Up Resources
Select Cloud > Resources to view the Resources page. Before resources can be configured, you need to know which agent machines are available to allocate to jobs. The Resources page displays all resources available to the CloudBees Flow server. This page is your Resources management center where you create, modify, or delete resources and see the resource status.
To view the Resource Pools page where you can manage the resource pools in CloudBees Flow, go to Cloud > Pools. To view the Zones page where you can manage the zones in CloudBees Flow, go to Cloud > Zones.
What is a Resource?
A resource is an agent machine where steps can execute. In addition:
-
Each resource has a logical name.
-
Each resource refers to an agent machine by its host name.
-
Multiple resources can be defined on the same physical host.
-
Each resource can be assigned to one or more pools, or one zone.
-
Each resource has a step limit that determines the maximum number of steps that can execute simultaneously on the resource.
In Create/Edit Resource panels, you define the number of steps that can run on a resource. Remember that setting Step Limit to "0" or leaving the field blank defaults to no step limit.
When CloudBees Flow allocates resources for a job and steps are executed on the resource, it considers the step limit, not the CPU load from the steps . The step limit for a resource in your system depends on the agent machine performance. For example, using unlimited as the step limit for a heavy load can slow the agent and cause less consistent agent performance if this is not managed properly.
What is a Resource Pool?
A resource pool is a group of interchangeable resources. For example, a pool of Windows servers. Naming a pool in a procedure step lets CloudBees Flow assign any resource from that pool to do the work for that step. By default, CloudBees Flow tries to balance the requests against the set of resources in the pool, but you can also define rules for how resources are selected.
To define a resource for a procedure step, you can:
-
Specify a resource or a pool name in a procedure step to execute that step on that resource/pool.
-
Define custom properties for your resources or pools.
-
Mark a resource as "exclusive" (the step acquires and retains its resource exclusively).
For example, if configuration information varies from resource to resource, you can use custom properties to hold this information and then reference it from procedure steps where it is needed. Suppose you have a pool of test machines where the test hardware is in a different location on each machine. You could define a property named "testLocation" on each resource, then pass this property to procedure steps using a reference such as $[/myResource/testLocation]. This approach lets you define procedure steps to run on any resource and automatically handle configuration differences.
| When the CloudBees Flow server and agents are installed on different hosts, make sure that the configuration for each agent specifies the Domain Name System (DNS) server. |
Resource Categories
-
Standard
-
Proxy
Standard Resources
This resource category specifies a machine running an installed CloudBees Flow agent on one of the supported agent platforms, as specified in the CloudBees Flow Installation Guide , Chapter 2, "System Requirements and Supported Platforms."
Proxy Resources
This resource category requires SSH keys for authentication. You can create proxy resources (agents and targets) for CloudBees Flow to use on numerous other remote platforms/hosts that exist in your environment. A proxy agent is a CloudBees Flow agent, channeling to a proxy target.
-
Proxy agent —This is an agent on a supported Linux or Windows platform, used to proxy commands to an otherwise unsupported platform. A proxy agent is a CloudBees Flow agent, channeling to a proxy target.
-
Proxy target —This is a machine on an unsupported platform that can run commands via an SSH server. Proxy targets have limitations, such as the inability to work with plugins or communicate with ectool commands.
For a step that will run on a proxy target, specify the Working Directory as the directory to which the step’s commandFile is uploaded from the proxy agent to the proxy target via SSH.
When a step runs on a proxy resource, the proxy agent performs the following tasks:
-
Uploads the
commandFileto the Working Directory on the proxy target via SSH. -
Working Directory—the step runs in this directory on the proxy target, which defaults to the UNIX path to the workspace
-
Creates a wrapper
shshell script to: -
CD to the Working Directory
-
Set COMMANDER_environment variables that exist in the proxy agent’s environment
-
Run the commandFile that was uploaded earlier
-
Uploads the wrapper script to the Working Directory on the proxy target
-
Runs the wrapper script on the proxy target
-
Cleans up script files on the agent and proxy target
Setting Up SSH Keys
For details about setting up SSH keys, see the KBEC-00049—Setting up SSH Keys in preparation to use a Proxy Agent KB article.
On UNIX, the CloudBees Flow agent looks in the ~/.ssh directory for the private and public key files to set up the SSH connection to the proxy target. Therefore, you should generate your key files in that directory.
On Windows, the CloudBees Flow agent does not presume a default location. Therefore, in the proxy resource definition you must specify the key file location. To do so, enter the following line in the resource “Proxy Customizations” field:
setSSHKeyFiles('c:\ foo\priv.key');
Optimizing Resource Scheduler Performance
The resource scheduler is the part of the CloudBees Flow server that schedules runnable job, process, and workflow steps to run on resources. The resource schedule runs as a CloudBees Flow singleton service , so in a cluster, it runs on only one node. If your resource scheduler schedules thousands of steps per minute, you can optimize its performance by using the Number of separate threads the resource scheduler attempts to split its work across server setting. This setting lets you run the scheduler in multiple threads to parallelize resource scheduling; the multiple threads still run as a singleton service and thus are all on the same node in a cluster. The setting is in the Administration > Server > Settings screen in the Automation Platform.
The setting specifies the number of “buckets” of work that the resource scheduler attempts to divide resources into, and thus the number of threads that it runs to handle these buckets of work. The range is 1 through 8. The default is 1 (one bucket). Depending on server workload and other details, setting it to more than 1 might increase resource scheduler throughput and thus might also increase overall CloudBees Flow server throughput.
For a value exceeding 1, the CloudBees Flow server tries to divide the lists of enabled resources and pools into that number of buckets so that each resource is in the same bucket as all of its pools, and each bucket size (measured by the number of resources and pools in it) is about equal. The division reoccurs (as part of the same database transaction) whenever:
-
A resource or pool is created, enabled, deleted, disabled, or renamed
-
The list of resources in a pool is modified
-
The server or a server node starts
Depending on system speed and the numbers of resources and pools, redivision could slightly delay these operations. During redivision, all the resource schedulers are paused, which delays the scheduling of steps.
| After changing the value, you must restart the CloudBees Flow server or cluster nodes so that the new value takes effect. You should restart all nodes as soon as possible after a value change to avoid problems. |
Potential Performance Increase with Parallelization
CloudBees Test Results
In general, the potential performance increase is small for a single-server CloudBees Flow installation and large for a cluster. CloudBees tested the sustained throughput (not the number of steps running concurrently) on a cluster with parallelization using the following scenario:
-
Five schedulers on a five node cluster
-
Up to 2400 agents
-
Very short steps (such as
echo hello world) to maximize the stress on the scheduler -
Several thousand steps scheduled per minute
-
Peaks of several thousand steps waiting to be scheduled…
-
Several hundred steps executing concurrently
The actual measured speedup was about 2.8 (limited by the speed of the database that processed the resulting steps).
Potential Speedup
A single step scheduler on a fast modern server can generally schedule 25-30 steps per second. This assumes a database round trip time of about ½ ms (which requires a good local connection to a fast database server). Five steps schedulers can at least triple that rate (and possibly more depending on database performance).
Situations Where Resource Scheduler Parallelization Might Not Be Advantageous
Parallelization might not be advantageous in the following situations.
Parallelization might not be effective if you:
-
Both frequently create, enable, delete, disable, or rename resources or pools or modify the list of resources in any pool (which likely means that you have automated one or more of these operations)
-
And have more than 1000 resources or pools, which causes the redivision to require about several seconds
You should not use parallelization if the resulting decrease in performance of these operations because of redivision is unacceptable. Also, any of the resource or resource pool changes as described above that cause a redivision will briefly pause parallelized resource schedulers (typically for several seconds). This briefly delays all jobs running on the server. Thus, if you modify resources so frequently that the resulting jobs delay decreases performance that exceeds the potential gain from parallelization, then you should not use parallelization.
Resource pools with unbalanced buckets
If you have one (enabled) pool or a set of overlapping (enabled) pools that contains more than 1/ N th (in other words, more than its share) of all resources, then using a parallelization value greater than N will not divide resources into perfectly equal buckets of work. If the largest bucket exceeds about twice the size of the smallest, a warning appears in the CloudBees Flow log at each redivision (such as at server startup).
The warning indicates the pool most responsible for the problem. If the warning appears, then disabling or subdividing the pool (if the pool’s purpose allows it) might fix the problem. If not, you should avoid parallelization (or at least keep the value sufficiently low).
Resources in the Same Pool During Peak Workload
If during peak workload, the list of all runnable steps that can be scheduled usually contains mostly steps being run on resources in the same pool or an overlapping set of pools (most likely because they are usually broadcast steps in the same job), then parallelization is unlikely to increase performance significantly. This is because at any point time, most of the workload would still be on a single thread.
Determining the Best Resource Scheduler Setting
If CloudBees Flow server performance is a concern, then unless an issue discussed above keeps you from using parallelization, you should experiment with using it. You should monitor performance (particularly the amount of time that steps spend in the “Runnable” state) and try various values to find the best one for your setup and usage pattern. Whether enabling this feature helps, and what the optimum setting is, depend greatly on your usage pattern and how your resources and resource pools are arranged. It can even decrease performance.
For one CloudBees Flow server, you should use a value of 1 or 2. For a CloudBees Flow cluster, the best value is probably between 1 and a few over the number of cluster nodes . You should first try a value of 2 for one server or a value equal to the number of nodes in the cluster and then experiment from there. Any resulting performance increase depends on your usage pattern such as volume of jobs and the volume of resources.
Optimizing Oracle Database Performance When Using Parallelization
If changing the value speeds up your CloudBees Flow server, it increases the load on your database server and can make the database server the performance bottleneck (particularly for a cluster). If you experiment with using a value greater than 1, you should also work with your database administrator (DBA) to optimize database performance (for example, to ensure that table/index fragmentation is under control).
Oracle database performance optimization is complex because of Oracle’s numerous performance tuning tools and mechanisms. Their proper use is outside the scope of this manual. However, your Oracle DBA should know that:
-
The resource scheduler interacts heavily with tables with names of the form EC_SM_*.
-
The contents of these tables are short-term data that is deleted typically within a few minutes after the relevant job ends.
This means that the contents of these tables and their indexes turn over fast and are also normally empty if the CloudBees Flow server is idle. Unless your CloudBees Flow workload is stable and always consistent, they can thus interact poorly with the default table/index statistics-gathering mechanism used by the Oracle performance optimizer unless you “lock” the statistics while the CloudBees Flow server is under typical high and extended job load. (In which case the performance optimizer will still rapidly claim that the “locked” statistics have become stale.) So on Oracle, unless your CloudBees Flow workload is stable and always consistent, you should use a “locked” snapshot of the statistics for these tables and their indexes. Depending on workload and usage patterns (and especially your deletion pattern), this might also be true for several other tables in the CloudBees schema. Your Oracle DBA should work with you to identify those tables.
Creating a Resource
Click the Cloud tab in the CloudBees Flow web interface to go to the Resources page.
At the top right-side of the table, click the down arrow next to the plus sign and select Create Resource or Create Proxy Resource link to see the New Resource or New Proxy Resource panel.
From either panel, New Resource or New Proxy Resource, click the Help link in the upper-right corner of the page to access the Resources Help topic in the Automation Platform to see descriptions and other information to assist with filling in the fields.
Gateways and Zones
CloudBees Flow provides the capability of establishing security zones for agents and repository servers.
What is a Zone?
A zone consists of a collection of resources that can directly communicate with each other. In a large corporation, a zone could encapsulate a physical site, and communication between any two sites occurs through firewalls.
What is a Gateway?
The details of this connection information are recorded in a gateway object in CloudBees Flow. Using the example in Cross-Zone Communication as a reference, a gateway object consists of the following information:
-
Name of a gateway resource in one zone (GatewayAgent1)
-
Name of a gateway resource in another zone (GatewayAgent2)
-
Host/port GatewayAgent2 uses to communicate with GatewayAgent1 (for example, the firewall IP address in ZoneB)
-
Host/port GatewayAgent1 uses to communicate with GatewayAgent2 (for example, the firewall IP address in ZoneA)
Cross-Zone Communication
The following figure shows an example gateway and zone configuration with two zones and three machines.
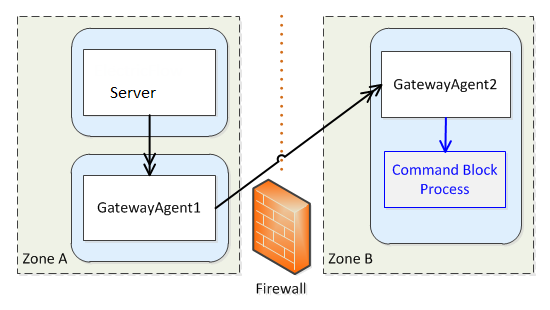
Cross-zone communication is managed by proxying requests through specially marked resources called “gateway resources”. In the previous example, if the CloudBees Flow server wants to run a command block process step on an agent in Zone B, it issues its request through GatewayAgent1. The request includes extra metadata that instructs GatewayAgent1 to forward the request to the target agent. The firewall is configured to allow connections from GatewayAgent1 to GatewayAgent2. It is also configured to allow connections from GatewayAgent2 to GatewayAgent1. This is necessary because API communication (CLI commands and the step completion message) is sent from GatewayAgent2 on its own outbound connection to the server (through GatewayAgent1).
Because the firewall separates two private networks, there’s no guarantee that IP address ranges in one network do not overlap with those of the other. When either gateway agent wants to connect to the other, the gateway agent uses an IP address to the firewall that is valid for its side of the firewall.
Support for Gateways
The previous example shows two zones for simplicity, but CloudBees Flow supports an unlimited number of zones, including chained zones. For example, if a third zone called Zone C is only accessible from Zone B via GatewayAgent3 (in Zone B) and GatewayAgent4 (in Zone C), the server could issue a request to GatewayAgent1, which forwards the request to GatewayAgent2, which forwards it to GatewayAgent3, which forwards it to GatewayAgent4.
Also, for resiliency, CloudBees Flow supports having multiple gateway agents between two zones. If one gateway agent goes down, the system will detect the failure and route all requests through the other gateway agent.
Setting Up Workspaces
CloudBees Flow provides each job step with an area on the disk it can use for "working files" and results. This disk area is called a job workspace.
A job step can create whatever files it needs within its workspace, and CloudBees Flow automatically places files in the workspace, such as step logs. Normally, a single workspace is shared by all steps in a job, but it is possible for different steps within a job to use different workspaces. The location of the job step workspace is displayed on the Job Details page for the job under "Details" for the step.
To create a new workspace
CloudBees Flow can handle any number of workspaces.
-
To define a workspace from the web interface, click the Cloud > Workspaces tabs.
-
On the Workspaces page, click the Create Workspace link at the top right-side of the table and the New Workspace web page is displayed.
Click the Help link in the top-right corner of the web page for assistance with filling in the fields to create a workspace. To see the Workspaces Help topic now, click Workspace—create new or edit existing workspace .
After you create a workspace specification, you will see it listed on the Workspaces page.
Setting Up Email Configurations
This topic describes how to set up an email configuration. It must be created and configured before you set up email notifications, also referred to as email notifiers at the platform level. Then you can send them to individuals or groups.
If you have multiple users or groups in remote locations who use a different mail server, you need to create additional email configurations to accommodate those locations if they receive CloudBees Flow notifications.
Creating an Email Configuration
To create an email configuration in the platform GUI:
-
Click Administration > Email Configurations to go to the Email Configurations page.
-
Click Add Configuration to go to the New Email Configuration page.
-
Enter information in the fields on the page.
There are two ways to get help in entering information in the fields: Click Email Configuration—create new or edit existing email configuration to go to the Email Configuration help topic. If you are in the platform GUI, click the Help link in the upper-right corner of the page to see descriptions and other information.
After the email configuration is created, you will see it listed in the table on the Email Configurations page.
Setting Up a Source Control Configuration
You must configure your source control system to communicate with the CloudBees Flow server if you plan to takes advantage of the CloudBees Flow Continuous Integration Dashboard and associated functionality and Preflight functionality—both of these features are designed to work with a number of source control (SCM) systems.
-
Continuous Integration Dashboard—use this feature to create continuous integration schedules for your build environment. The Continuous Integration Manager is the front-end user interface for the ElectricSentry Continuous Integration engine.
-
Preflight—use this feature to build and test developer code before it is committed to the code base for your product.
CloudBees Flow installs (bundles) and supports numerous source control types. After creating a source control configuration, your entry will appear in the table on the Source Control Configurations web page—to see this web page, select the Administration > Source Control tabs.
If the SCM you prefer is not listed here, see the Plugin Manager page (Administration > Plugins) for a list of all currently available SCM plugin integrations available for CloudBees Flow. To configure a different SCM, see the Help topic associated with that plugin.
Select one of the following links to go to the source control configuration page to configure your SCM system:
The Continuous Integration Dashboard has its own Help topic. For more information on ElectricSentry or Preflights builds, see their respective help topics: * ElectricSentry * Preflight Builds
Setting Up Directory Providers
CloudBees Flow uses account information from multiple sources. In most cases, the primary account information source is an external LDAP or Active Directory repository: both user and group information is retrieved from the repository. Local users and groups can be defined within CloudBees Flow.
To specify a directory provider
CloudBees Flow includes a web page to facilitate adding your existing LDAP or Active Directory users and groups to CloudBees Flow.
-
To access the Directory Providers web page, select the Administration > Directory Providers tabs.
-
Click the Add Active Directory Provider or the Add LDAP Provider link to add a new provider.
Depending on which Add… Provider link you choose, you will see either the New Active Directory Provider or the New LDAP Provider web page. From either page, click the Help link in the upper-right corner of the page. The Help topic describes each field on either web page so you can easily enter information in the forms to have CloudBees Flow use your existing user or group account information.
To see the Directory Provider Help topic now, click Directory Providers—create new or edit existing directory providers . After adding a provider, you will see it listed in the table on the Directory Providers web page.
Enable/Disable Local CloudBees Flow Users
Two server settings properties are supplied for local CloudBees Flow users (both are "on" by default):
-
enableAdminUser—if set to'0', attempts to log in as the 'admin' user are denied as if the user did not exist -
enableLocalUsers—if set to'0', attempts by a non-admin local user to log in are denied as if the user did not exist
These settings are stored in properties in the '/server/settings' property sheet and can be set from ectool by calling:
ectool setProperty /server/settings/enableAdminUser 0
Or, these settings can be set from the automation platform web interface:
-
Select the Administration > Server tabs.
-
At the top of the page, select the Settings link.
| Disabling these properties takes effect only for new sessions. Existing sessions continue to function "as-is" until the user logs out and attempts to log in again. |
Setting Up a Separate Web Server
Using the Web Server Host server setting ensures correct URLs in email notifications from the CloudBees Flow server if the Apache web server name differs from the CloudBees Flow server name. For example, if the servers are on separate machines. This setting is on the Administration > Server > Settings page of the Automation Platform.
You can enter <hostname> or <hostname>:<port> if the port number is other than 80. If a load balancer is used for the web server, then enter the load balancer host. If this value is not set, then access to this property returns the value from /server/hostName.
wrapper.conf Properties
If you need to edit the wrapper.conf file, see https://wrapper.tanukisoftware.com/doc/english/properties.html for complete information about property formats.