Automating your release pipelines makes the path to production seamless, efficient and reduces risk. To maximize these benefits in your pipelines, it is imperative to include effective automated testing strategies. Tests in lower environments, like development, testing and QA, should mimic the production environment as closely as possible. Waiting on having the right components ready or incomplete and unrealistic data can slow down the entire process and increase the your cycle time, impacting your time and cost per release. Integrating test data management and service virtualization directly into your release pipeline means efficient test cycles while providing reliability and ensuring production readiness.
Test data management allows testing against production-like data in preproduction environments. Test data management tools provide the ability to create and manage test data that is anonymized and random, but also provides coverage of all test cases—and then support the use of that data in testing.
Service virtualization enables use of virtual services instead of depending on readiness of production services that might not be ready or available in lower environments. The virtual services emulate the components in production and allow comprehensive testing that can happen more frequently and earlier in the pipeline.
Example: Pipeline with test data management and service virtualization
Test data management and service virtualization strategies should be automated and integrated into applications deployments and release pipelines to enable comprehensive and reliable system testing. This means provisioning the virtual services and representative virtual data to create environments that provide full coverage of any scenario or corner case.
This example shows strategies for using these practices in a release pipeline in CloudBees Flow. In this example, the EC-Parasoft plugin is used to integrate with Parasoft as the tool to manage and import testing data and create environments with virtual services for testing. The same patterns and strategies can be used to model pipelines using other test tools by replacing calls to Parasoft with the appropriate calls to the other tool.
The pipeline has two stages, QA and Prod, for deploying the motorbike store application in each environment and then running system tests. In the QA stage, test data must be imported, and virtual services must be generated in order to create a complete environment for system testing. Test data and service virtualization are not required in the Production stage because the production environment has all production components and data available.
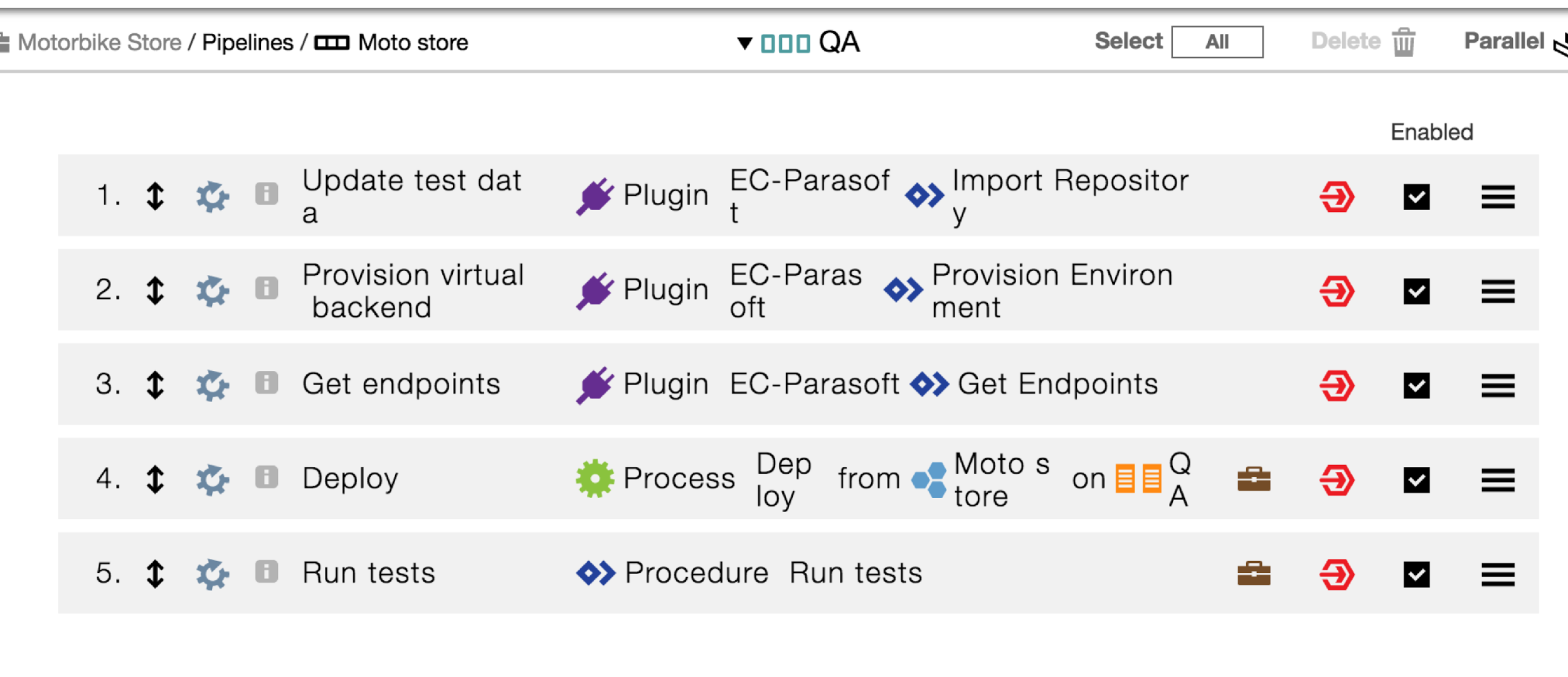
QA stage
The QA environment does not have access to all required production services and requires test data to run full system tests. Before starting the application deployment or tests, the first tasks in the pipeline prepare the test data and virtual services for the environment.
-
The first step imports the test data to the server using the EC-Parasoft plugin action to import a repository.
-
Next, the “provision environment” plugin action is called with parameters to provision a Parasoft environment with the required virtual services.
-
The endpoints for the virtual services are retrieved from the newly provisioned environment to be used in the tests.
-
Now that the environment and data are prepared, the motorbike store application is deployed by calling the deploy process for the model.
-
Finally, system tests are run for the application using the test data and provisioned environment with virtual services.
After the QA stage is complete, an automated gate is based on a condition that checks the test results. If greater than 97% of tests passed, the gate is automatically approved, and the pipeline is promoted to the Production environment. If the tests results do not meet this threshold, the gate is rejected, and the pipeline stops execution.This is just an example of automated quality gates. You can add any conditional check to automatically control the pipeline progress.

Production Stage
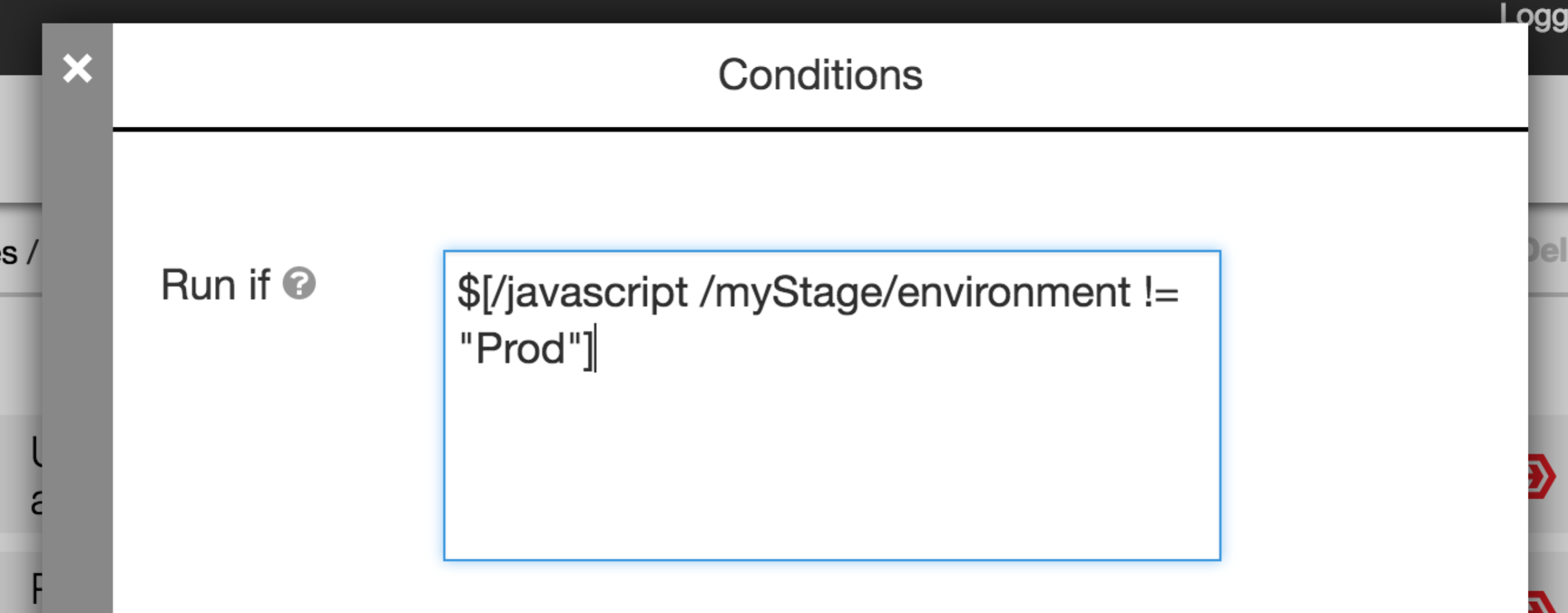
The Production stage does not require test data or virtual services. Conditions on the tasks are used to skip the steps for importing test data and provisioning virtual services. The condition checks which environment is being run in the stage by checking a property stored on the stage. If it is the production environment, the test data management and service virtualization steps are skipped for the stage.
This example uses Parasoft for test data management and service virtualization. Other tools can be leveraged with the same approach in modeling the pipeline
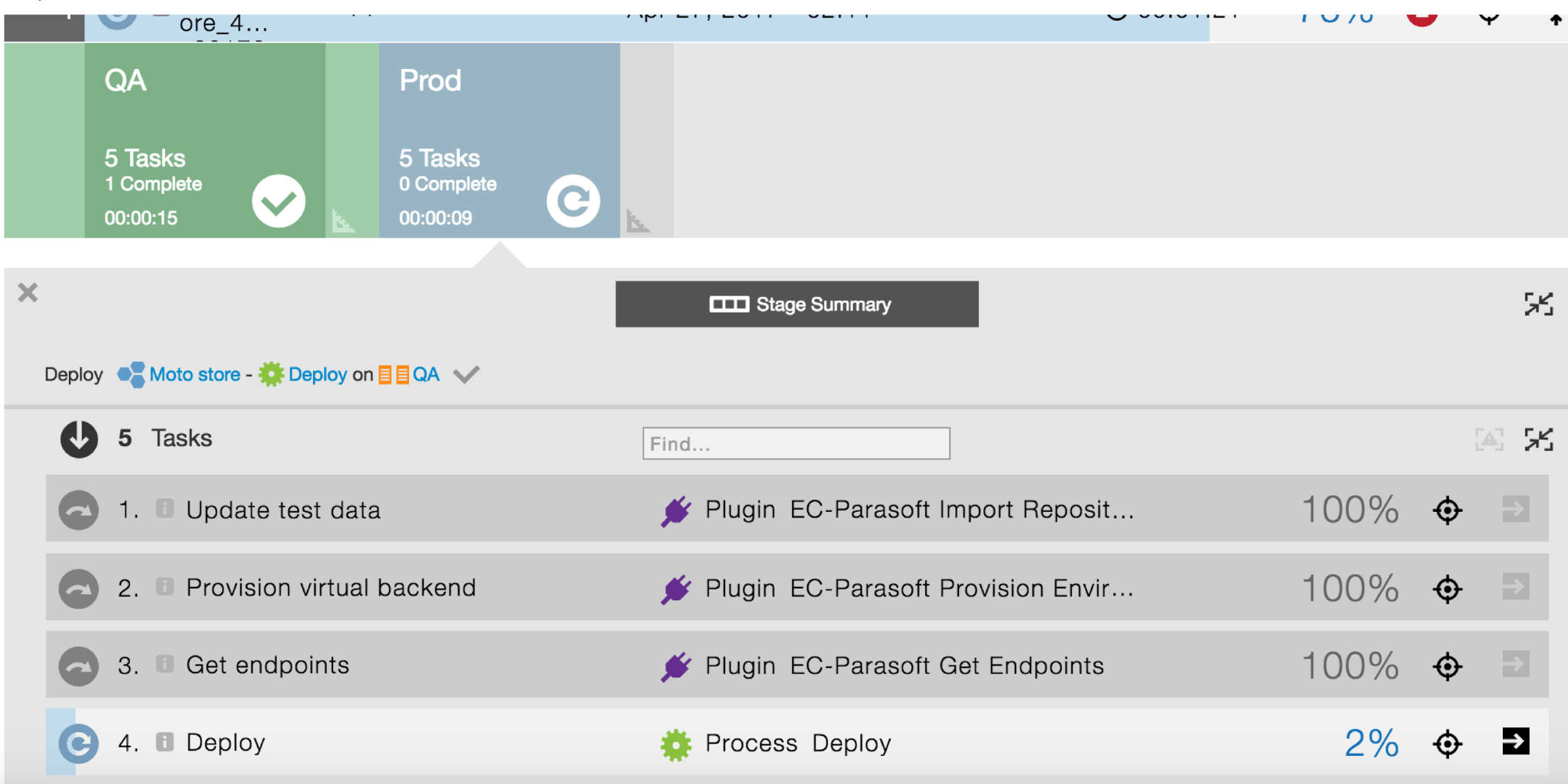
When the pipeline is run, all of the test preparation steps are skipped, and the application deploy process is run directly:
Other Strategies and Actions
Instead of calling test data management and service virtualization from pipeline tasks, these actions could also be called from within the application deployment process itself. Similar conditions can be used to skip these steps for production deployments. The condition can reference the current environment being deployed to, and can be set on the entry into the steps that need to be skipped.
Aside from importing test data as show in the example, integrations with Test Data Management systems can also be used to manage and update data set. This is done with the EC-Parasoft plugin using the “Update Data Set” and “Update Record” procedures.
See the EC-Parasoft plugin help file for details: https://electric-cloud.com/plugins/directory/p/parasoft .