CloudBees Flow provides each job step with an area on the disk it can use for "working files" and results. This disk area is called a job workspace. (The job workspace defaults to a directory under the workspace directory.)
-
A job step can create whatever files it needs within its workspace, and CloudBees Flow automatically places files in the workspace, such as step logs. Normally, a single workspace is shared by all steps in a job, but it is possible for different steps within a job to use different workspaces.
-
The location of the job step workspace is displayed on the Job Details page for the job under "Details" for the step.
-
Workspaces are grouped together, with workspaces for different jobs allocated as children of the same workspace root . When you define procedures, you can specify which workspace roots to use, then CloudBees Flow creates a child directory within that workspace root for the job’s steps to use.
-
The term "workspace" is used at different times to refer to either a job workspace or a workspace root. Depending on the context, it should be easy to discern which "workspace" is being discussed or referenced.
Defining Workspaces
CloudBees Flow can handle any number of workspace roots, which are defined by selecting the Cloud > Workspaces tabs on the web interface. To create a workspace root, provide a workspace name and three file paths for jobs to access the workspace:
-
Workspace name—The workspace name must not have trailing spaces. When two workspaces have similar names, such as "Server1" and "Server1 " (with an extra space at the end), the database records them as two entries, one without trailing spaces and one with trailing spaces.
If you run a job against one of these workspaces, it may hang and not proceed because CloudBees Flow is waiting for a resource, an available workspace, or a step to complete.
-
UNC path —A UNC path that Windows machines can use to access the workspace via the network, such as
//server/share/x/y/z. You must ensure this path is accessible on any resource where the workspace is used. -
Drive path — Windows path, using a drive letter that refers to the same directory as the UNC path. Before running a job step using the workspace, the CloudBees Flow agent creates a drive mapping for this path to match the UNC path. For example, if the UNC path is
//server/share/x/y/zand the drive path isN:, the agent will mapN:to//server/share/x/y/z. If the drive path is ` N:/y/z` then the agent will mapN:to//server/share/x.The directories in the drive path after the drive letter (
y/zin the preceding example) must match the last directories in the UNC path. -
UNIX path —A path used on UNIX machines to access the workspace via the network, typically using an NFS mount. You must ensure appropriate mounts exist on all resources where the workspace is used.
If your environment contains Windows machines only, you can omit the UNIX path, and if your environment contains UNIX machines only, you can omit the UNC and Drive paths.
During the CloudBees Flow installation, you had the option of defining a workspace. If you defined a workspace, it was named "default" and will be the default workspace for all jobs, as described below.
By default, remote workspaces are accessed with the agent user’s credentials. For Windows resources, you can override that user’s credential by attaching a credential to the workspace. Using a credential attached to a workspace is useful if the agent machine is not a member of the domain, but the workspace is located on a machine in the domain. An attached credential for a domain user allows the agent to manipulate the workspace as that domain user.
Using Workspaces
The simplest way to use workspaces is to define a single workspace named "default" that is readable and writable on all resources, and never specify any other workspace information. With this approach the default workspace will be used for all steps in all jobs.
However, you can also arrange for different jobs to use different workspaces, or even for different steps within a single job to use different workspaces.
You can specify a workspace name in any of the following CloudBees Flow objects:
-
If you specify a workspace in the definition of a procedure step, it applies to that step.
-
If you specify a workspace in the definition of a procedure, it applies to all steps in the procedure.
-
If you specify a workspace in the definition of a project, it applies to all steps in all procedures defined in that project.
-
If you specify a workspace in the definition of a resource, it applies to all steps assigned to that resource.
If workspaces are defined in several of these places, the workspace for a particular step is chosen in priority order corresponding to the list above: a workspace specified in a step takes priority over all others, followed by a workspace in the procedure, project, and finally resource. If no workspace is specified in any of these locations, the workspace named "default" is used.
Workspace Directory Names
A job workspace directory name, within its workspace root, is derived from the name of the job. For example, if a job named "job_63" uses a workspace whose root directory is //ec/workspaces, the job workspace directory will be //ec/workspaces/job_63. Changing the name of a job has no impact on workspace names: the initial name of the job is always used for workspace directory names.
A job is allocated a single job workspace only within a particular workspace root, which will be shared by all steps that specify that root. For example, suppose a job has 5 steps: 3 steps specify workspace A and 2 steps specify workspace B. The 3 steps that specify A will all share a single directory under A, and the other 2 steps will share a single directory under B.
Working Directories
By default, each job step begins execution with its current working directory set to the top-level directory in the job’s workspace. A job step can override this location by specifying an explicit working directory. If a job step specifies a relative path for its working directory, the path is relative to the top-level workspace directory.
Workspace Accessibility
The simplest way to set up CloudBees Flow is to make every workspace root accessible on every resource. This accessibility mode provides the most flexibility and simplifies CloudBees Flow system management
Unfortunately, some environments cannot allow such universal access. For example, some sites do not provide file sharing between UNIX and Windows machines. In large enterprise environments where CloudBees Flow is shared among multiple groups, you may want to partition resources among the groups and limit access by each group to the other groups' resources. In the most extreme case, you may not have network file sharing at all. CloudBees Flow can handle all of these cases.
If a workspace root is not accessible on a particular resource, you should not use that workspace in any step that runs on the resource. If you do, the resource will not be able to create the job workspace directory and the step will stall until the issue is resolved. A workspace root (on a resource) must be both readable and writable to be used for job steps.
Local Workspaces (Disconnected Workspaces)
Normally, workspaces are shared, which means if the same workspace is used on different resources, they see the same set of files. However, it is possible to define a local workspace (also referred to as a disconnected workspace), which means it will refer to a different local directory on each resource where it is used.
-
To define a local workspace on Windows, specify a local path such as ` C:/Windows/Temp/ecworkspace` for the drive path.
-
For UNIX, specify a local UNIX path such as
/usr/tmp/ecworkspace. Local workspaces are advantageous because they do not require remote network access and access may be faster in some cases.
However, you cannot share workspace information among job steps running on different resources.
Web servers "ask" the relevant agent for access to log files in workspaces. The agent streams the file back to the web server, which then streams the log file to your browser. Solaris, MacOS, and HPUX agents must transfer log files to a workspace proactively so a Linux or Windows agent can access them for the web server—this task can be made easier, using the ecremotefilecopy tool. See ecremotefilecopy for details.
|
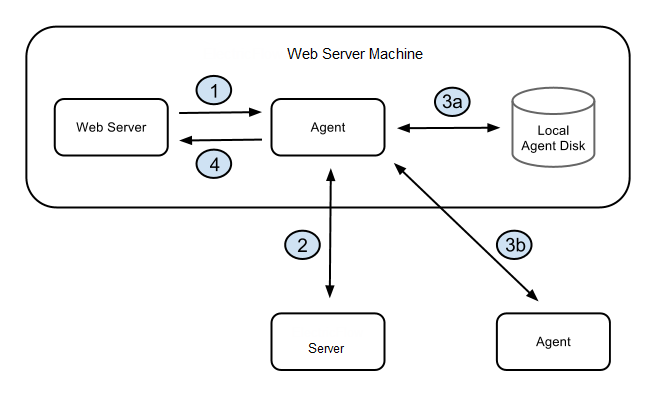
The diagram illustrates the architecture when the web server requests a log file and you have defined a local workspace.
-
The web server asks the local agent to retrieve the file from a workspace.
-
The agent (local to the web server) asks the CloudBees Flow server how to find the workspace, and the CloudBees Flow server replies with a route to an agent and validates the session ID.
-
The route to the agent that has the file could be:
-
The agent (local to the web server) gets the file from its local disk.
-
The agent gets the file from some other agent.
-
-
The agent (local to the web server) sends the file to the web server.
Access control to restrict access to workspaces
You can restrict access to workspaces using the CloudBees Flow access control mechanism. Before a step can use a workspace, it must have the "execute" privilege on the workspace, where "it" means the CloudBees Flow user ID under which the step executes (the project principal). You can set permissions on a workspace to enable or disable access as you choose.
Impersonation and workspaces
Before a job step can use a particular workspace, three access limitations must be satisfied:
-
The job step must have execute access to the workspace object. If not, CloudBees Flow aborts the step with an access control violation. See the Access Control Help topic for details.
-
The workspace must be accessible on the resource where the step runs. If not, the CloudBees Flow agent is unable to create the step’s log file and the step’s execution will fail. See Workspace Accessibility (above) for more information.
-
The Windows or UNIX agent account and/or job step must have read/write access to workspace files. If not, the step’s execution will fail in one of several ways. This issue is the topic of this section.
Potentially, two system accounts can impact each job step execution:
-
The first account is the one used by the CloudBees Flow agent—you selected this account when CloudBees Flow was installed. The agent account must have the ability to write the workspace root directory (to create the job workspace directory), and it must have the ability to write the job workspace directory to create log files.
-
The second account is the one under which the step executes. If the step does not use user impersonation (in other words, no credential has been specified for it), the step runs under the same account as the agent so there are no additional issues. However, if the step is running with credentials, the credentialed account must also have read/write access to the workspace area.
Because of these requirements, you may end up with a configuration where any job step running in a workspace can read or write any file under that workspace root, including files from other jobs that share the same workspace root. In many environments this solution works, but in some situations you may want to prevent one job from accessing files from a different job.
To create job privacy, run all of the job’s steps with credentials for a separate account. In addition, run a job step at the beginning of the job that creates a subdirectory within the job workspace and change the protection on that directory to permit access to the credentialed account only. Next, place all private files for the build in the protected subdirectory.
These files will not be accessible to other jobs or the agent. The top-level directory in the job workspace still needs to be accessible to the agent so it can read and write log files, but everything in the lower-level directory will be private.
CloudBees Flow managed files
CloudBees Flow automatically places certain files in the top-level job step workspace directory:
-
Step logs —When a step’s command executes, its standard output is redirected to a log file unique to that step. The log file name is derived from the step name and its unique identifier within CloudBees Flow. For example, a step named "step1" will have a log file with a name like "step1.2770.log", where 2770 is a unique identifier assigned by CloudBees Flow. A unique identifier is needed in situations where the same step name occurs multiple times in a job such as multiple invocations of a single nested procedure.
-
Postprocessor logs —If a step specifies a postprocessor, standard postprocessor output is redirected to a file in the workspace. The postprocessor output file will have a name similar to the step log. For example, "step1.2770-postp.log".
-
Diagnostic extracts —If a postprocessor extracts diagnostic information from a step’s log file, it usually places that information in an XML file in the top-level job workspace directory, and then it sets a property that contains the file name. The CloudBees Flow postp postprocessor uses file names like diag-2770.xml, where 2770 is the unique identifier for the step. Other postprocessors may use different file names.
Disk space management
The current CloudBees Flow version does not provide a facility for automatically deleting old workspaces. You are responsible for deleting obsolete job workspaces yourself. If you delete a job, CloudBees Flow does not automatically delete its workspace. (A future CloudBees Flow version may provide automated facilities for identifying and deleting obsolete workspaces—until then, you may wish to create a procedure that runs on a regular schedule and deletes old job workspaces.)
ecremotefilecopy
When CloudBees Flow agents (on platforms other than Linux or Windows) run steps that create log files in a workspace the CloudBees Flow web server cannot access (through Linux or Windows agents), use the ecremotefilecopy tool to recreate job logs so they are visible on those CloudBees Flow agents, which then enables the web server to retrieve and render those log files.
ecremotefilecopy is installed with CloudBees Flow. For details, see ecremotefilecopy .