Many software systems make use of secret data for authentication purposes such as user passwords, secret keys, access tokens, and certificates. Traditionally, these systems could be secured using physical intranet networks and login details for each person in an organization. However, modern DevOps requires agility and safety in a far more dynamic and complex environment than physical intranets where any individual component of the system cannot necessarily trust any other part of the system. This concern isn’t exclusive to public cloud computing because of the prevalence of security vulnerabilities and profit motivations for attackers to compromise, use networked computing resources, or exfiltrate proprietary information.
Managing machine identities
Identity and access management now take on key roles in managing machine and human identities. These machine identities, such as service accounts or application roles, can be created and destroyed on demand along with corresponding virtual machines, containers, microservices, and clients. Centralizing access controls for both human and non-human principals enables detailed audit logs of physical resource usage and billing, and when combined with a secrets management system, allows credentials to be automatically rotated and updated without recompiling and redeploying applications when a critical API key or other leaked secret is inevitably compromised.
Applying security best practices with secrets managers
Secrets managers comprise software solutions that primarily manage the storage, encryption, and retrieval of secrets. Additionally, secrets managers can also provide audit logs, identity and access controls, secrets rotation, and certificate authorities. Furthermore, secrets managers provide integration points, enabling applications to use a standardized method of obtaining, using, and securing these secrets. As security best practice dictates, an agile security incident response should include removing hard-coded secrets from applications, and electing instead to store secrets in a secrets manager, replacing them in the code with indirect references.
Using secrets managers in a CI environment
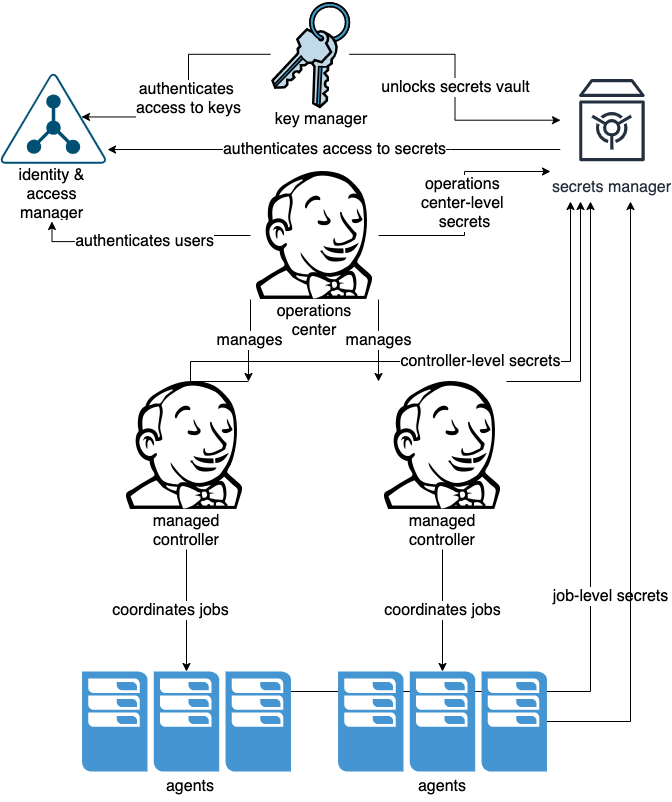
In a continuous integration (CI) environment like CloudBees CI, these secrets may encompass vast permissions and access rights. Similarly, at the infrastructure level, secrets will have high level permissions to manage infrastructure and the applications running on them. It is important to minimize and partition access controls required by automated actors (virtual machines, containers, microservices, IoT devices, etc.). This equally applies to the access controls on the secrets needed by each actor.
Selecting a secrets manager
Selecting an effective secrets manager depends on existing infrastructure choices. Secrets management is closely tied with key management, including certificate authority public key infrastructure (PKI), and identity and access management, so existing infrastructure needs play an important role in selecting a particular secrets manager. For example, many cloud providers have secret managers available as a service which offer varying levels of functionality and integrate with or provide their own key management services and information and access management (IAM) services. Kubernetes and Docker both have secret APIs that allow for independent secrets manager backends or can use sidecar secrets injection and other container-specific deployment patterns. Independent secrets managers that can be deployed to both traditional and modern infrastructure include Vault, Conjur, Keywhiz, and Knox, which all provide at minimum generic operating system-level integration points like environment variables or files in addition to various convenient integrations with common software.
As adoption of secrets management matures in an organization, dynamic features like time-bound or single-use secrets become applicable for further minimizing the scope of compromised secrets. Secrets managers typically offer some method of grouping access permissions to secrets into permission bundles in the form of groups, roles, client IDs, application IDs, or similar authorization patterns. Most secrets being managed are used by services rather than by humans, so it may not be immediately obvious how to organize secrets in such a way to minimize access scope or how to form logical dependencies between secrets and services to avoid locking yourself out. The layer at which a secrets manager integrates with CloudBees CI is heavily dependent on the runtime environment being used. A few examples follow.
Using secrets managers on modern cloud platforms
CloudBees CI on modern cloud platforms uses Kubernetes. Kubernetes provides a Secrets API which allows for secrets to be injected into containers at runtime as files or environment variables. The default implementation of the Kubernetes’ Secrets API stores these values encrypted in Kubernetes’ etcd storage, the distributed key/value database used by Kubernetes for managing its state.
The Secrets API has been available from Kubernetes 1.13 onwards. Independent secrets managers offer Kubernetes integration either by allowing a service to authenticate with the secrets manager using its own ServiceAccount or by integrating with the Kubernetes Secrets API directly. Using Kubernetes Secrets as a secrets manager allows for identity and access management to remain centralized in Kubernetes to avoid maintaining service roles in multiple places.
When using Kubernetes directly for secrets, ServiceAccounts should correspond to each team or product using them. This connection allows access controls for secrets to be managed by the same access controls for the usage of Kubernetes itself. The CloudBees operations center ServiceAccount should have access to any additional secrets needed for central management such as the ServiceAccount tokens used by the CI controllers. Service accounts and secrets access controls can be configured most easily in CloudBees CI by creating separate Kubernetes namespaces for each team with its own managed controller; separate Kubernetes namespaces provide simpler access controls than individual service accounts in the same namespace for the same application.
When sharing a controller between multiple products, teams, or environments, many of the benefits of container access controls become less effective and require a single controller to have access to the equivalent of multiple ServiceAccounts which is NOT recommended.
|
Using secrets managers on traditional platforms
CloudBees CI on traditional platforms uses or integrates with many other technology stacks such as Docker, public cloud platforms, bare metal servers, and virtual machines. Docker has its own Secrets API similar to Kubernetes, though it only implements minimal secrets management without specifying access controls or other related functionality and instead defers that to the orchestration engine. When deploying CloudBees CI using automation tools like Terraform, Ansible, Puppet, or even homemade shell scripts, an additional access control layer is introduced in the form of the secrets needed to orchestrate cloud services, VMs, networks, load balancers, Ingress points, and other infrastructure.
These automation products all have their own native secrets management offerings, though it’s recommended to stick with a more general secrets manager to avoid having to administer multiple secrets managers. These secrets should be limited to their own operator-level group/role in the secrets manager so that CloudBees CI does not have direct access to those secrets. Partitioning secrets in this sort of hierarchical way minimizes the harm that can result from compromised secrets and make them easier to audit. It also provides a natural pattern for organizing dependencies of secrets to avoid the top level from directly accessing secrets from lower levels by storing just the credentials necessary for each lower level group or role.
Traditional platforms also include systems that already manage identity and access controls in some form or another, including Kerberos, LDAP, Active Directory, and other directory servers. These solutions typically offer authentication and authorization for both humans and services alike. Some secret managers can use groups/roles/objects defined in these directories to configure their own access controls. Centralizing authorization metadata in directory servers is comparable to using Kubernetes ServiceAccounts or other identity and access management APIs. Directory servers must be configured to be highly available using replica servers for failover so that infrastructure problems affecting the directory have less of a chance of causing cascading failures as applications become unable to authenticate with the secrets manager.